Promise
单元测试
容器
react.js
归并排序
pycharm
SAP ABAP
keil
文字
CVE-2013-4547
Hudi
网络字节序
r语言
PageRank
hevc
vue3生命周期
jdbc
web前端期末大作业
PM项目管理
多任务学习
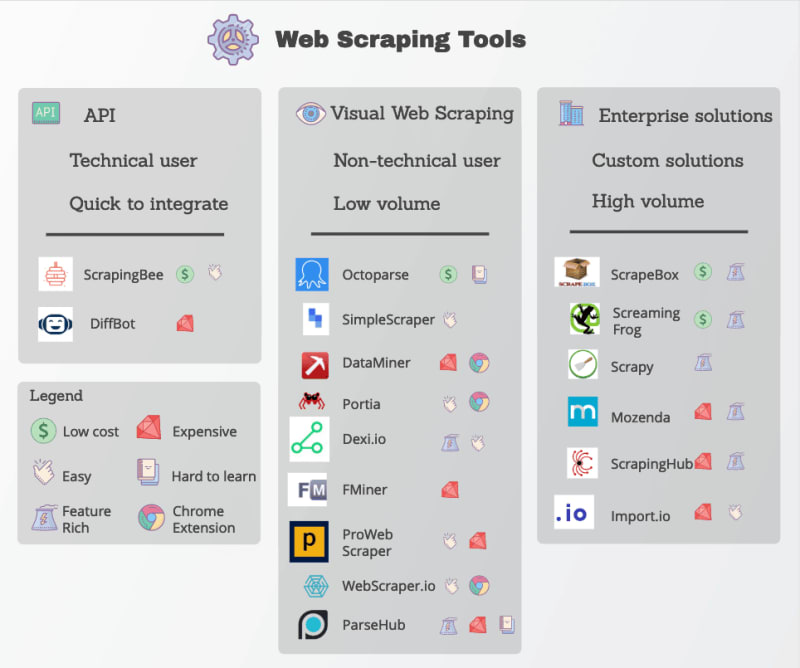
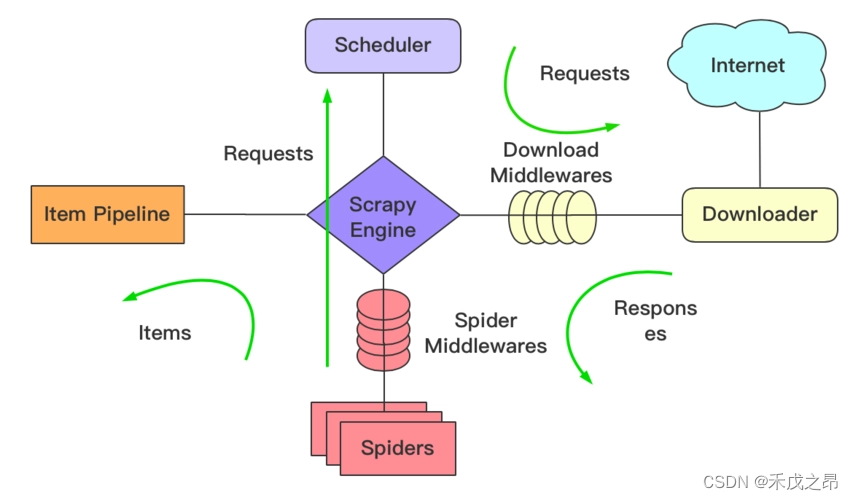
网络爬虫
2024/4/11 14:20:49
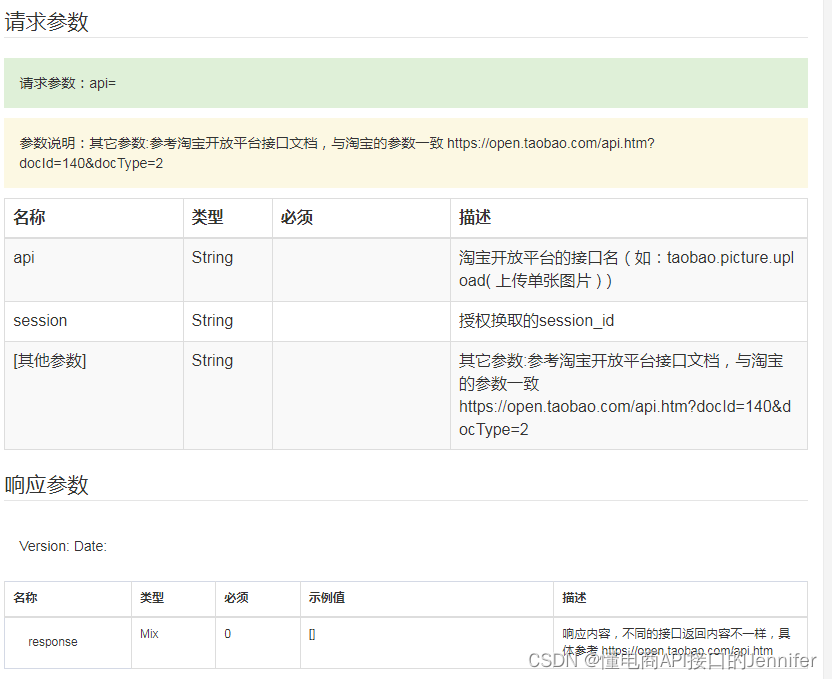
京东工业根据ID取商品详情 API 调用文档(参数说明、调用示例)
item_get-根据ID取商品详情 API测试工具
vipmro.item_get 公共参数
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_g…
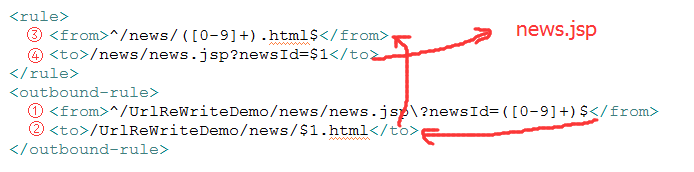
web安全之--UrlRewrite
最近在做一个项目,在做项目的过程中发现,由于自己的命名规范,显示在url地址栏中的信息如果不加修饰,很容易被人理解并且改写。如果让别人看不懂自己网站上的url地址栏的内容是不是非常好呢,于是自己便发时间去查找资料…

Python爬虫之读取数据库中的数据
之前几篇我们一直在研究如何从网站上快速、方便的获取数据,并将获取到的数据存储在数据库中。但是将数据存储在数据中并不是我们的目的,获取和存储数据的目的是为了更好的利用这些数据,利用这些数据的前提首先需要从数据库按一定的格式来读取…
拼多多API拼多多商品数据商品信息获取API免费试用
item_get-根据ID取拼多多商品详情
测试pinduoduo.item_get 公共参数
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_g…
淘宝有哪些值得抓取的数据?通过API可以获取到哪些数据?
淘宝是中国最大的在线购物平台,有丰富的数据可供抓取。以下是一些值得抓取的数据以及通过API可以获取到的数据:
1. 商品信息:包括商品标题、价格、销量、评价等。
2. 店铺信息:包括店铺名称、店铺信用、开店时间等。
3. 物流信…
写点东西《什么是网络抓取?》
写点东西《什么是网络抓取?》 什么是网络抓取? 网络抓取合法吗? 什么是网络爬虫,它是如何工作的? 网络爬虫示例 网络抓取工具 结论 您是否曾经想同时比较多个网站上同一件商品的价格?或者自动提取您最喜欢的…

【python爬虫】9.带着小饼干登录(cookies)
文章目录 前言项目:发表博客评论post请求 cookies及其用法session及其用法存储cookies读取cookies复习 前言
第1-8关我们学习的是爬虫最为基础的知识,从第9关开始,我们正式打开爬虫的进阶之门,学习爬虫更多的精进知识。
在前面几…
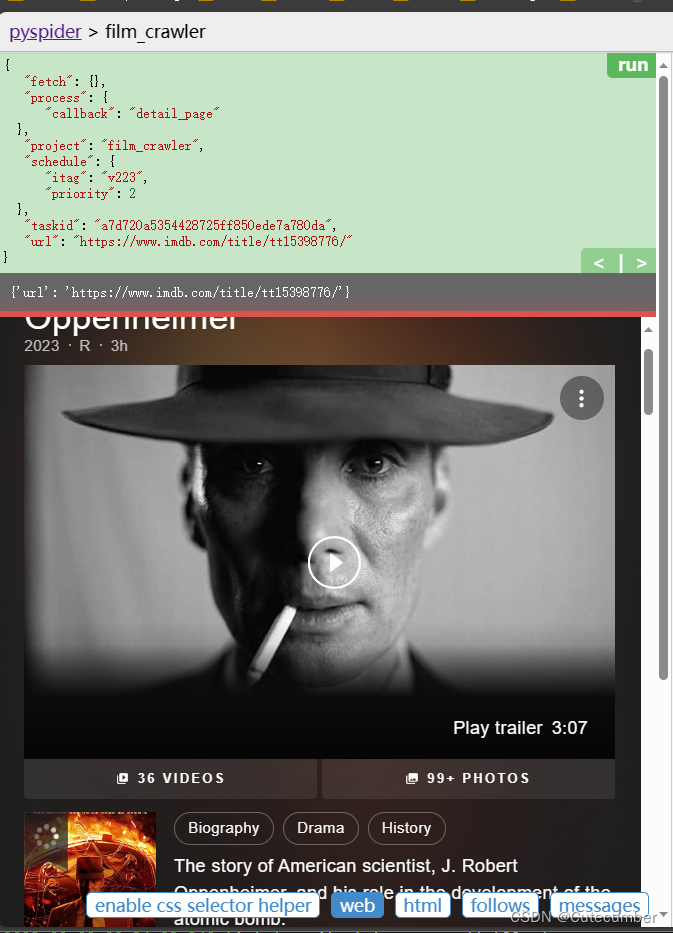
Docker部署pyspider webui显示页面太小的解决方法
进入docker容器,输入以下指令来获取pyspider的位置
python -c "import pyspider;print(pyspider)"如图所示
然后进入到 /opt/pyspider/pyspider/webui/static 修改debug.min.css
vi debug.min.css使用vi的查找命令,然后回车。即可找到该样…

BloomFilter——大规模数据处理利器
BloomFilter——大规模数据处理利器 Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。 一. 实例 为了说明Bloom Filter存在的重要意义,举一个…

爬虫系列(二) Chrome抓包分析
在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析
1、测试环境
浏览器:Chrome 浏览器
浏览器版本:67.0.3396.99 (正式版本) (32 位)
网页分析工具:开发者工具
2、…

采集发布到WordPress自定义参数
Wordpress有自定义设置的参数,一般是用户自行设置,或主题和插件扩展新增的自定义参数,要怎么发布?
WordPress主题或插件扩展新增的自定义参数,一般是保存到数据库的wp_postmeta表中。
先去数据库中确定对应自定义参数…
一键采集拼多多热销爆款-API采集不黑号
随着电商行业的迅猛发展,越来越多的商家投入到电商运营中。在这个竞争激烈的市场中,如何快速获取并处理商品信息,掌握市场动态,成为制胜的关键。利用API来获取拼多多的商品数据,可以帮助商品快速便捷获取到数据。
ite…
Python获取信息并保存MongoDB实例
前言 Python连接数据库是十分必要的操作,我这次用的是MongoDB数据库保存数据。这类的文章一般都不容易审核,所以就不多说废话,直接开搞,完整源码放在最后,有需要自取。 效果展示: 导入所需要的相关库
imp…

三方接口调用设计方案
在为第三方系统提供接口的时候,肯定要考虑接口数据的安全问题,比如数据是否被篡改,数据是否已经过时,数据是否可以重复提交等问题
在设计三方接口调用的方案时,需要考虑到安全性和可用性。以下是一种设计方案的概述&a…

网络爬虫-Robots协议
1、概念 2、案例:京东的Robots协议 三、Robots协议的基本语法 四、Robots协议的遵守方式
1、Robots协议的使用 2、对Robots协议的理解

利用Pholcus框架提取小红书数据的案例分析
前言
在当今互联网时代,数据的获取和分析变得越来越重要。爬虫技术作为一种数据采集的方法,被广泛涉及各个领域。在本文中,我们将介绍如何使用Python Spark语言和Pholcus框架来实现一本小红书数据爬虫的案例分析。
开发简述
Go语言作为一种…

外贸电商商品如何做好上架工作?
跨境电商业务的蓬勃发展已经成为互联网行业的热点话题之一。不论是将海外货源卖回国内,还是通过国内货源销往海外,跨境电商平台都面临着如何实现商品上架的关键问题。在这篇文章中,将探讨成功上架商品的关键步骤。 一、准备好接口。
跨境电商…
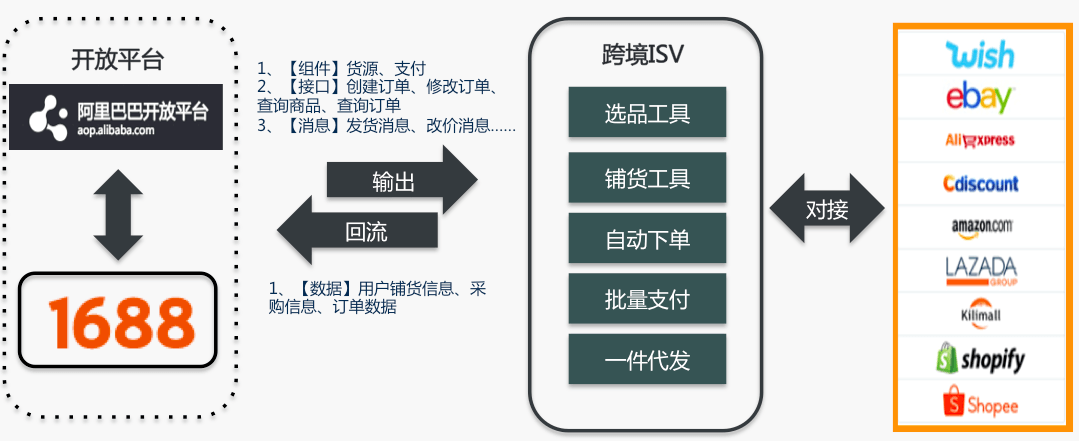
1688买家API接口跨境卖家需要的API接口
1688作为深耕产业带多年的数字供应链平台,近两年不仅在年轻消费群体中热度飙升,在跨境侧也有不俗表现。
11月19日,1688总裁余涌在1688跨境寻源通计划发布会上透露,1688平台拥有100万的源头厂商,每年服务6500万的B类买…

Fiddler 微信小程序抓图教程(傻瓜式|汉化版|狗看了直呼内行)
前言 本篇文章主要给大家详细讲解如何用Fiddler爬取微信小程序的图片,内容图文并茂,流程非常简单,我们开始吧。 目录
获取软件并打开点击工具设置相关代理如何抓图答疑总结 一、获取软件并打开
1、通过百度网盘下载获取安装包(链接是永久的…
爬虫系列(三) urllib的基本使用
一、urllib 简介
urllib 是 Python3 中自带的 HTTP 请求库,无需复杂的安装过程即可正常使用,十分适合爬虫入门
urllib 中包含四个模块,分别是
request:请求处理模块parse:URL 处理模块error:异常处理模块…
爬虫系列(九) xpath的基本使用
一、xpath 简介
究竟什么是 xpath 呢?简单来说,xpath 就是一种在 XML 文档中查找信息的语言
而 XML 文档就是由一系列节点构成的树,例如,下面是一份简单的 XML 文档:
<html><body><div><p>…

淘宝免费爬虫数据 商品详情数据 商品销售额销量API
场景:一个宽敞明亮的办公室,一位公司高管坐在办公桌前。
高管(自言自语):淘宝,这个平台上商品真是琳琅满目,应该有不少销售数据吧。我该怎么利用这些数据呢?
突然,房间…

Python爬虫实战之研招专业目录抓取(共享源码)
今天给大家分享一个实战项目,利用 Scrapy 框架抓取研招网的招生目录信息。包括各个招生单位的所有招生专业信息以及考试课程信息等,最终效果如下。(相关源码等资源,可关注公众号:Python资源分享,回复 yanzh…

怎么使用动态代理IP提升网络安全,动态代理IP有哪些好处呢
随着互联网的普及和数字化时代的到来,网络安全问题越来越受到人们的关注。动态代理IP作为网络安全中的一种技术手段,被越来越多的人所采用。本文将介绍动态代理IP的概念、优势以及如何应用它来提升网络安全。 一、动态代理IP的概念 动态代理IP是指使用代…

Amazon图片下载器:利用Scrapy库完成图像下载任务
概述
本文介绍了如何使用Python的Scrapy库编写一个简单的爬虫程序,实现从Amazon网站下载商品图片的功能。Scrapy是一个强大的爬虫框架,提供了许多方便的特性,如选择器、管道、中间件、代理等。本文将重点介绍如何使用Scrapy的图片管道和代理…
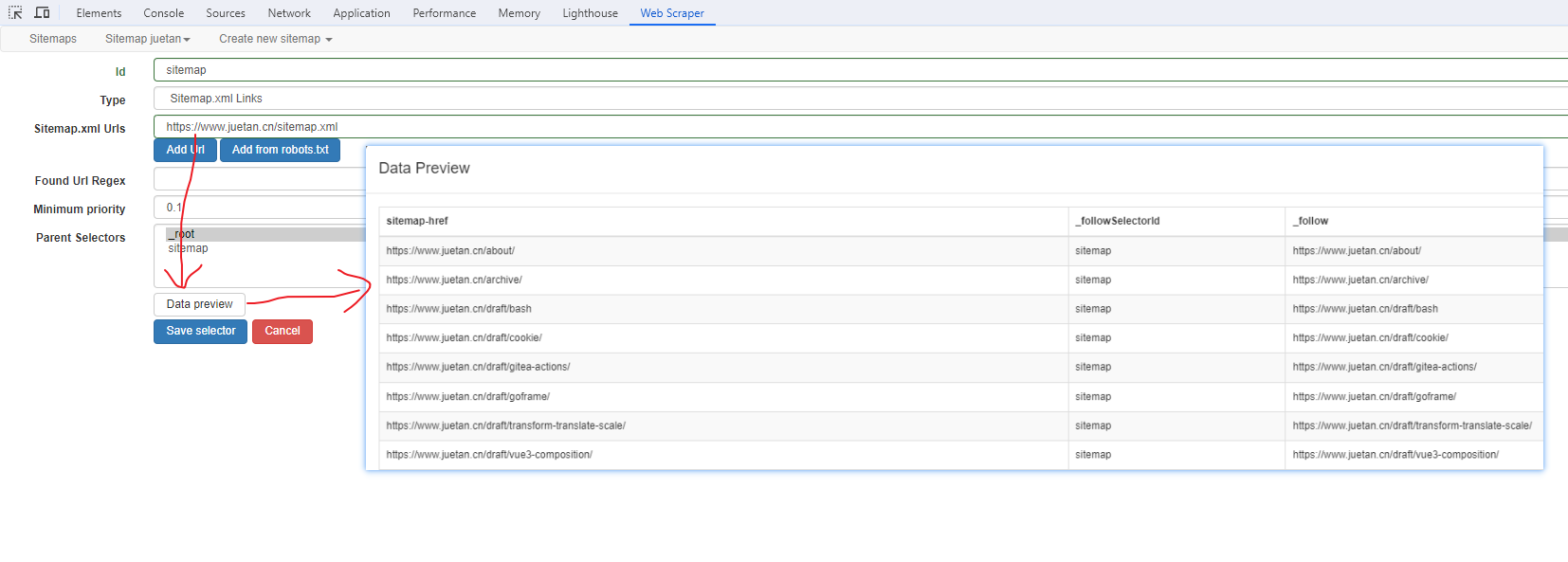
浏览器插件:WebScraper基本用法和抓取页面内容(不会编程也能爬取数据)
Web Scraper 是一个浏览器扩展,用于从页面中提取数据(网页爬虫)。对于简单或偶然的需求非常有用,例如正在写代码缺少一些示例数据,使用此插件可以很快从类似的网站提取内容作为模拟数据。从 Chrome 的插件市场安装后,页面 F12 打开…
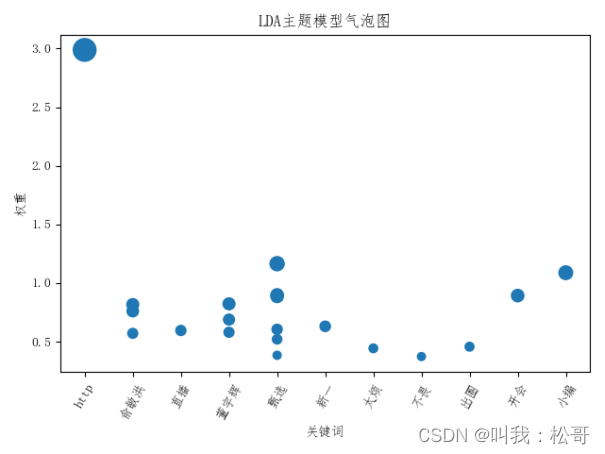
基于网络爬虫的微博热点分析,包括文本分析和主题分析
基于Python的网络爬虫的微博热点分析是一项技术上具有挑战性的任务。我们使用requests库来获取微博热点数据,并使用pandas对数据进行处理和分析。为了更好地理解微博热点话题,我们采用LDA主题分析方法,结合jieba分词工具将文本分割成有意义的…
基于Python的B站(哔哩哔哩)视频评论采集,可破解反爬手段,想爬几条爬几条
它通过输入Bilibili视频的av号、BV号或链接,然后使用指定的cookie和请求头信息发送HTTP请求来获取视频的评论数据。然后,它将评论数据解析为CSV格式,并保存到指定的文件中。
具体实现过程如下:
导入所需的库:request…
海外動態IP在網頁抓取方面的應用指南
作為互聯網提取大量數據的強大工具,網路抓取徹底改變了企業收集和分析數據的方式,為他們提供推動決策過程的重要參考。有效的網路抓取通常需要使用特定的海外動態IP代理工具。
在本文中,我們將瞭解什麼是代理抓取、為什麼使用海外動態IP代理…
Android Market应用商店优化-关键词及描述
有很多人,包括一些报刊杂志,都一直在试图说服我去写一篇有关应用商店优化的博文,好吧,现在我终于妥协了。这一直都是美联录音器(AL Voice Recorder)这款应用成功的关键所在,至今为止它已经被下载…

【Python_Scrapy学习笔记(十一)】基于Scrapy框架的下载器中间件添加Cookie参数
基于Scrapy框架的下载器中间件添加Cookie参数
前言
本文中介绍 如何基于 Scrapy 框架的下载器中间件添加 Cookie 参数。
正文
1、添加中间件的流程
在 middlewares.py 中新建 Cookie参数 中间件类在 settings.py 中添加此下载器中间件,设置优先级并开启
2、基…
拼多多开放平台订单接口接入说明
一、概述
拼多多开放平台提供了一系列的订单接口,开发者可以通过这些接口来获取和处理拼多多的订单数据。本文将详细说明如何接入这些订单接口,以及在使用过程中需要注意的事项。
二、接口介绍
订单查询接口:通过此接口,您可以…
关于反反爬虫技术:对限制连续请求时间的处理
一般的反爬措施是在多次请求之间增加随机的间隔时间,即设置一定的延时。但如果请求后存在缓存,就可以省略设置延迟,这样一定程度地缩短了爬虫程序的耗时。
下面利用requests_cache实现模拟浏览器缓存行为来访问网站,具体逻辑如下…
淘宝开放平台订单接口免申请审核接入规则
大家都知道,想要实现自动化批量获取淘宝的商品订单数据,离不开淘宝开放平台API接口。想要获取API调用权限,需要经过淘宝开放平台的严苛审核流程。并且,现在平台基本不开放新的应用权限了。像很多做ERP的公司,他们的客户…

打破常规思维:Scrapy处理豆瓣视频下载的方式
概述
Scrapy是一个强大的Python爬虫框架,它可以帮助我们快速地开发和部署各种类型的爬虫项目。Scrapy提供了许多方便的功能,例如请求调度、数据提取、数据存储、中间件、管道、信号等,让我们可以专注于业务逻辑,而不用担心底层的…
JS逆向分析某枝网的HMAC加密、wasm模块加密
这是我2022年学做JS逆向成功的例子,URL:(脱敏处理)aHR0cHM6Ly93d3cuZ2R0di5jbi9hdWRpb0NoYW5uZWxEZXRhaWwvOTE 逆向分析:
1、每次XHR的GET请求携带的headers包括:
{"X-ITOUCHTV-Ca-Timestamp":…

爬虫爬取数据时怎么配置代理IP来精准导航分析大数据?
在这个数字盛宴中,每一刹那都充满了无数的信息流转。就像瀑布中的水滴,每一滴都承载着可能性。爬虫代理IP与穿云API就像是这场盛宴中的精准导航仪,帮助我们捕捉那些最有价值的信息滴点,确保在这个时代的快速迭代中,我们…
手把手教你调用电商API获取淘宝订单数据(内附详细源码)
接口名称:seller_order_list-获取卖出的商品订单列表
taobao.seller_order_list 公共参数
请求地址:https://api-sever.cn/taobao/seller_order_list
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥…
python爬取boss直聘数据(selenium+xpath)
文章目录 一、主要目标二、开发环境三、selenium安装和驱动下载四、主要思路五、代码展示和说明1、导入相关库2、启动浏览器3、搜索框定位创建csv文件招聘页面数据解析(XPATH)总代码效果展示 六、总结 一、主要目标
以boss直聘为目标网站,主要目的是爬取下图中的所…
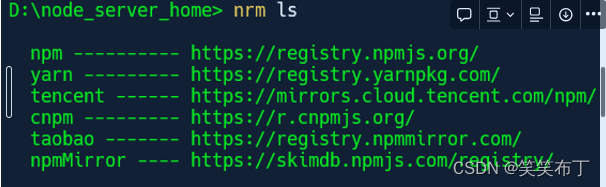
搭建nodejs服务器
简单搭建nodejs服务器,用于爬虫js逆向.
1、安装镜像源
下载nrm
npm install -g nrm
设置下载源:(最好使用npm源或者淘宝源)
例子:npm config set registry http://registry.npmjs.org
查看是否设置成功:…

巧用简单工具:PHP使用simple_html_dom库助你轻松爬取JD.com
概述
爬虫技术是一种从网页上自动提取数据的方法,它可以用于各种目的,比如数据分析、网站监控、竞争情报等。爬虫技术的难度和复杂度取决于目标网站的结构和反爬策略,有些网站可能需要使用复杂的工具和技巧才能成功爬取,而有些网…

python爬网站数据时遇到封IP+验证码+登陆限制怎么办?我的破解方法分享
python爬虫遇到封IP验证码登陆怎么办?我的破解技术分享 最近在在利用python网络爬虫技术从事数据聚合技术研发工作,刚开始主要是聚合工商的企业数据源、专利网的数据源、裁判文书网的数据源。做数据聚合研发首先的技术是Python,因为Python具有…

9.用python写网络爬虫,完结
前言 这是python网络爬虫的最后一篇给大家做个总结,且看且珍惜把! 截止到目前, 前几章本书介绍的爬虫技术都应用于一个定制网站,这样可以帮助我们更加专注于学习特定技巧。而在本章中,我们将分析几个真实网站ÿ…
小白学爬虫:手机app分享商品短连接获取淘宝商品链接接口|淘宝淘口令接口|淘宝真实商品链接接口|淘宝商品详情接口
通过手机APP分享的商品短链接,我们可以调用相应的接口来获取淘口令真实URL,进而获取到PC端的商品链接及商品ID。具体步骤如下:
1、通过手机APP分享至PC端的短链接,调用“item_password”接口。 2、该接口将返回淘口令真实URL。 3…
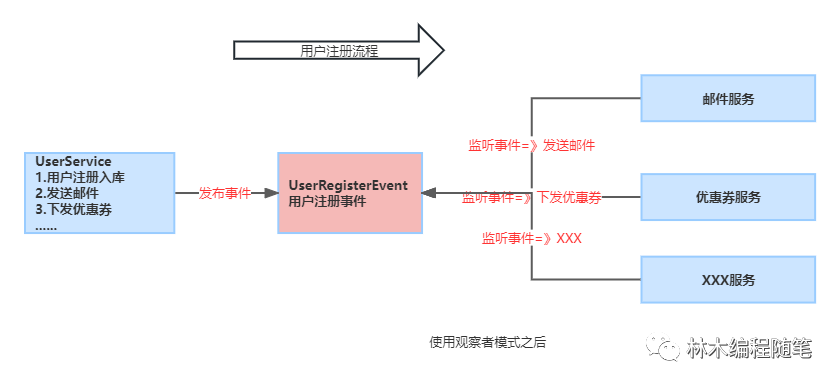
Spring Boot事件机制浅析
1、概述
在设计模式中,观察者模式是一个比较常用的设计模式。维基百科解释如下: 观察者模式是软件设计模式的一种。在此种模式中,一个目标对象管理所有相依于它的观察者对象,并且在它本身的状态改变时主动发出通知。这通常透过呼…

Haskell网络编程:从数据采集到图片分析
概述
爬虫技术在当今信息时代中发挥着关键作用,用于从互联网上获取数据并进行分析。本文将介绍如何使用Haskell进行网络编程,从数据采集到图片分析,为你提供一个清晰的指南。我们将探讨如何使用亿牛云爬虫代理来确保高效、可靠的数据获取&am…

从淘宝数据分析产品需求(商品销量总销量精准月销)
淘宝数据分析总体来说可以分为商品分析、客户分析、地区分析、时间分析四大维度(参考数据雷达的分析思路)。在这里我重点说商品分析。
在淘宝上开店的竞争还是非常激烈的,随便拿出一个单品就有很多竞品存在,所以做起来还是很难的,而想要在众…

业务安全情报23期 | 国庆前夕,又成功狙击一个倒卖机票的不法团伙
中秋国庆临近,热门航线机票预定量暴增。顶象防御云业务安全情报中心,监测到一个不法团伙进行虚假占座攻击,倒卖热门航班机票。在顶象协助下,该航空公司有效阻截多日的攻击,保障乘客购票利益。 热门航班遭到“倒票”攻击…
爬虫系列(十二) selenium的基本使用
一、selenium 简介
随着网络技术发展,目前大部分网站都采用动态加载技术,常见的有 JavaScript 动态渲染和 Ajax 动态加载
对于爬取这些网站,一般有两种思路:
分析 Ajax 请求,通过模拟请求得到真实数据,这…
深入探讨API:构建强大、有趣和互动的数字世界
随着数字技术的快速发展,应用程序接口(API)已经成为了现代软件开发和交互的核心组件。无论是你在使用智能手机应用程序,还是浏览网页,你都在与API进行交互。但是,什么是API?它如何工作ÿ…
【Python_Scrapy学习笔记(八)】基于Scrapy框架实现多级页面数据抓取
基于Scrapy框架实现多级页面数据抓取
前言
本文中介绍 如何基于 Scrapy 框架实现多级页面数据的抓取,并以抓取汽车之家二手车数据为例进行讲解。
正文
在介绍如何基于 Scrapy 框架实现多级页面数据的抓取之前,先介绍下 Scrapy 框架的请求对象 reques…
拼多多商品信息数据采集API接口 接入测试说明 一键批量采集下载多平台商品信息并导出宝贝链接!
当我们分析竞品以及选款复制时,往往需要先将商品信息采集下载下来,然而一个个去寻找商品并手动下载,显然是不现实的。
特别是做无货源店群的卖家,可能需要在不同平台采集商品信息,那么就需要用到适用不同平台的商品采…
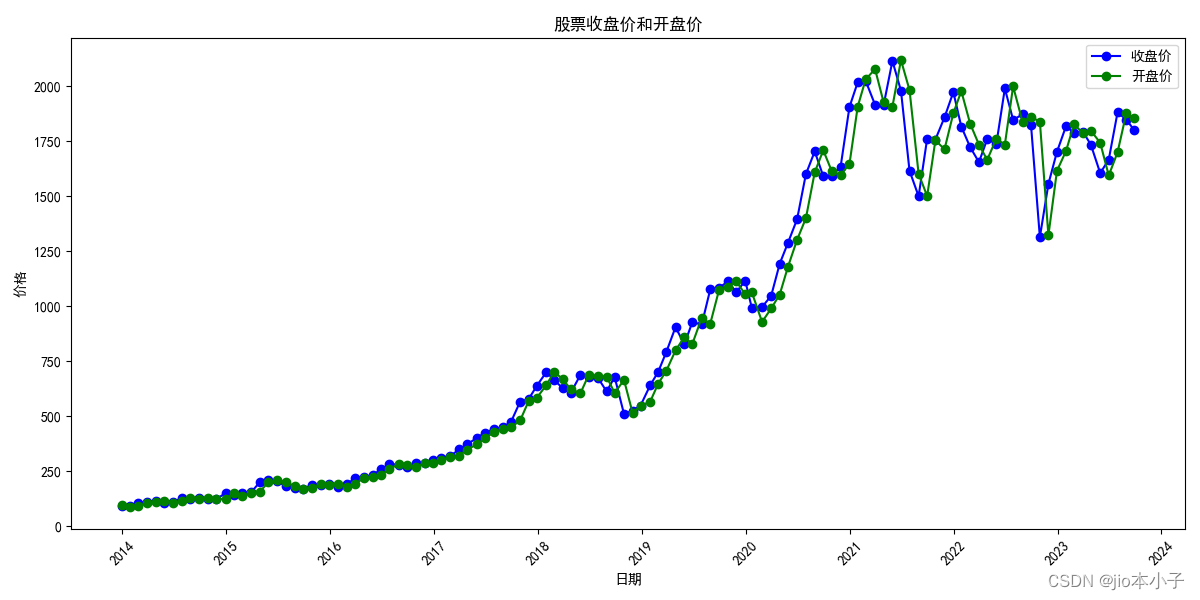
使用baostock获取上市公司情况
起因是有个不知道什么专业的同学问了我一题 cs:
import baostock as bs
import pandas as pd
import datetime
日线指标参数包括:date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,peTTM,pbMRQ,psTTM,pcfNcfTTM,isST
周…
探索API的无限可能:从基础知识到高级应用
随着科技的快速发展,应用程序接口(API)已经成为了软件开发和集成中的重要组成部分。API为应用程序提供了一种通用的通信方式,使得不同的软件组件可以相互协作,从而创造出更为丰富和复杂的软件系统。本文将深入探讨API的…
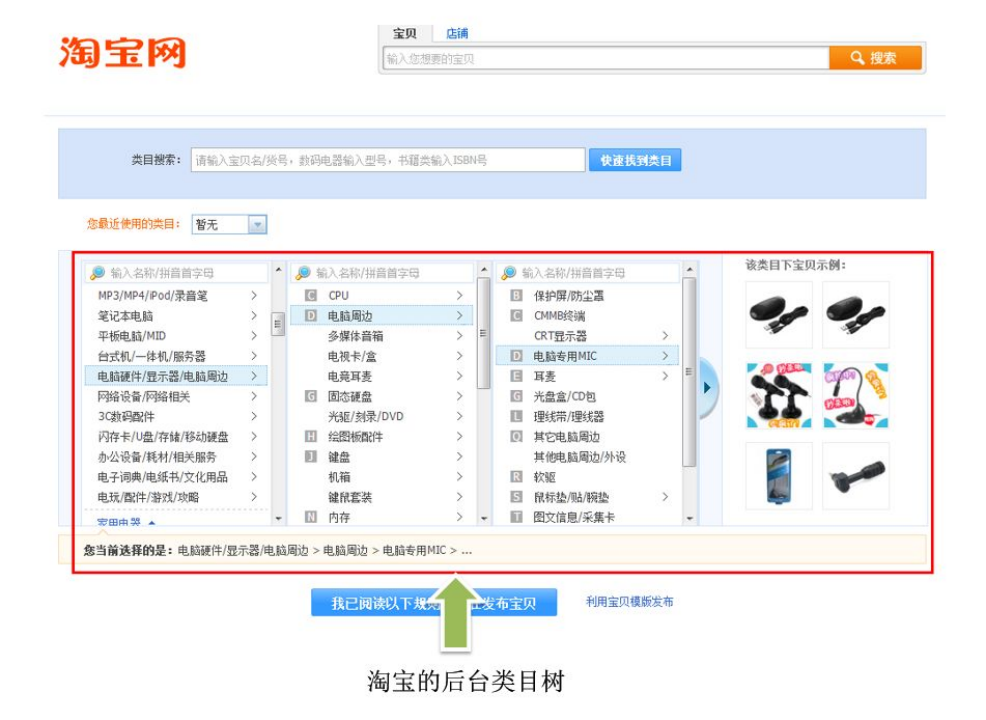
电商商品的前后台类目设计思路,小本本记下来(提供获取京东淘宝商品类目信息API 免费测试)
今天,我们来聊聊商品类目的设计思路。
商品是电商的根基,核心目标是销,也就是卖货。卖货可以多层理解,卖给谁,怎么卖,什么货,其实就是人货场的概念。
我理解的货,不仅是商品层面&a…

如何使用Puppeteer进行新闻网站数据抓取和聚合
导语
Puppeteer是一个基于Node.js的库,它提供了一个高级的API来控制Chrome或Chromium浏览器。通过Puppeteer,我们可以实现各种自动化任务,如网页截图、PDF生成、表单填写、网络监控等。本文将介绍如何使用Puppeteer进行新闻网站数据抓取和聚…

怎么使用好爬虫IP代理?爬虫代理IP有哪些使用技巧?
在互联网时代,爬虫技术被广泛应用于数据采集和处理。然而,在使用爬虫技术的过程中,经常会遇到IP被封禁的问题,这给数据采集工作带来了很大的困扰。因此,使用爬虫IP代理成为了解决这个问题的有效方法。本文将介绍如何使…

如何使用Ruby 多线程爬取数据
现在比较主流的爬虫应该是用python,之前也写了很多关于python的文章。今天在这里我们主要说说ruby。我觉得ruby也是ok的,我试试看写了一个爬虫的小程序,并作出相应的解析。 Ruby中实现网页抓取,一般用的是mechanize,使…


网络爬虫的原理是什么?
随着互联网的兴起,网络上的公开数据大多数都是以http(或加密的http即https)协议传输的。因此,我们将通过对爬虫技术的介绍并基于http(https)协议编写的爬虫教程供大家参考。
在Python的模块海洋里…
极简壁纸js逆向(混淆处理)
本文仅用于技术交流,不得以危害或者是侵犯他人利益为目的使用文中介绍的代码模块,若有侵权请练习作者更改。
之前没学js,卡在这个网站,当时用的自动化工具,现在我要一雪前耻。
分析
第一步永远都是打开开发者工具进…

Selenium + Chrome 网络爬虫学习笔记(从环境搭建开始,适合新手)
在实际的网络数据抓取过程中,经常会发现一些网页内容在网页源代码中查找不到的情况,因为这些内容都是通过JavaScript动态生成的,此时,使用普通的requests库无法直接获取相关内容。这时候就需要借助于Selenium模拟人操作浏览器&…
常用开放API大全,调用文档地址
以下是一些常用的开放API大全及其对应的调用文档: Google Maps API:提供地图、定位、导航和地理信息相关的API,文档地址:https://developers.google.com/maps/documentation Twitter API:用于获取和发布Twitter上的数…
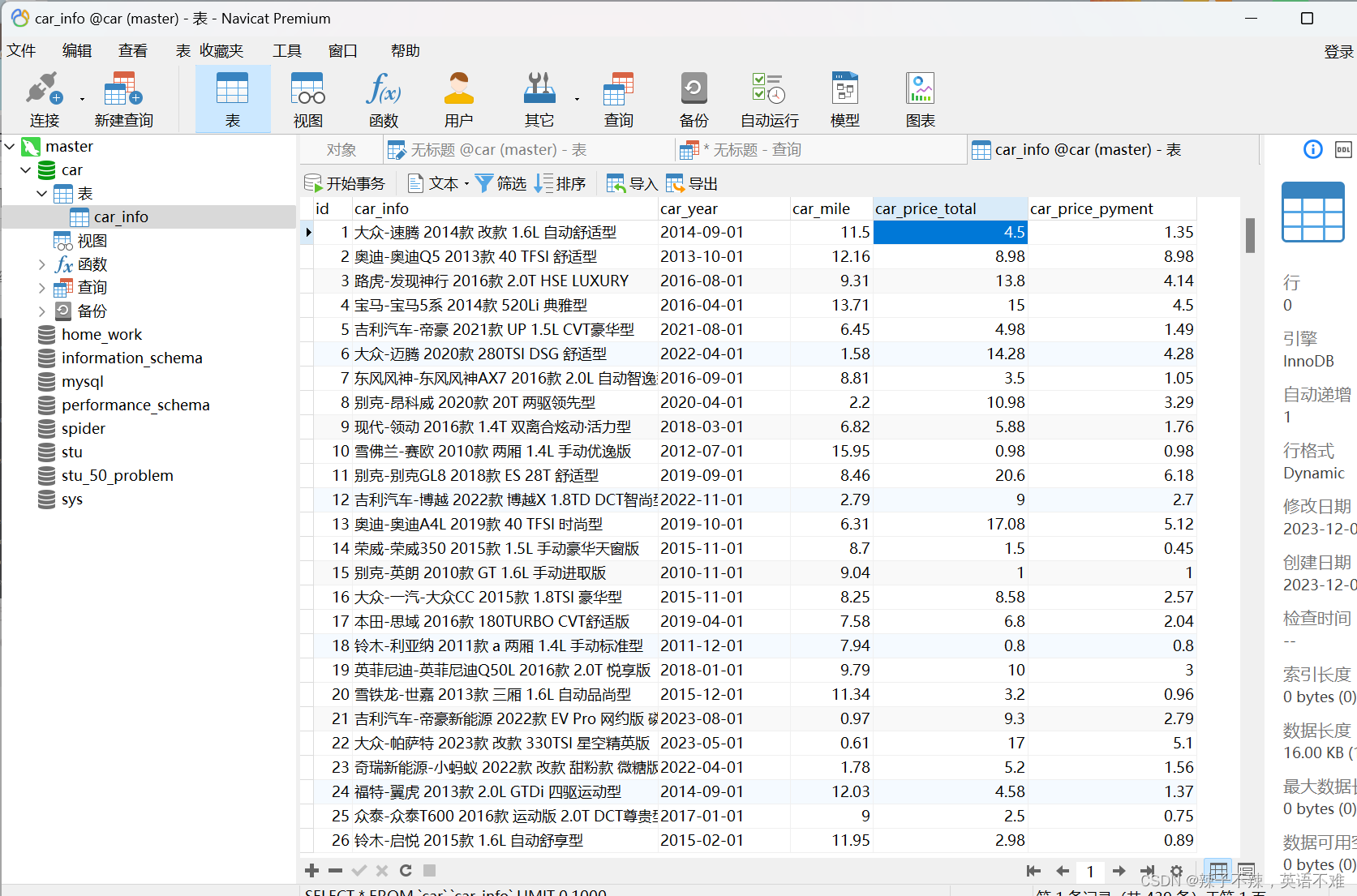
【爬取二手车并将数据保存在数据库中】
爬取二手车并将数据保存在数据库中 查看网页结构分析爬取步骤解密加密信息将密文解密代码: 进行爬取:爬取函数写入解密文件函数和获取城市函数解密文件,返回正确字符串函数保存到数据库 运行结果 查看网页结构分析爬取步骤
可以看出网页使用…
淘宝按关键字搜索淘宝商品 API 参数及返回值说明 翻页展示 含调用示例
淘宝关键字搜索接口,是复原我们在淘宝购物时,在搜索栏内输入关键字,即可获取到相关商品列表,商品信息齐全,支持翻页展示。同时,传入参数sort可按价格排序,也可筛选响应价格段的商品。商品信息是…
Python爬虫:Session、Cookie、JWT
当你在Python中进行网络爬虫时,需要处理会话(Session)、Cookie和JWT(JSON Web Token)时,以下是更详细的介绍和示例:
Session(会话):
会话用于维护用户的状态…
java读取网页内容,并保存
利用java进行读取网页内容并保存。参数为url链接。 使用到的jar文件:
commons-logging-1.2.jarhttpclient-4.5.1.jarhttpcore-4.4.3.jar package com.crawler;import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.i…
调用API来获取拼多多的商品数据的详细步骤和注意事项
本文旨在详细介绍如何调用API来获取拼多多的商品数据,并阐述相关的技术实现和注意事项。通过本文的阅读,读者将了解如何运用API技术从拼多多平台上获取商品信息,并具备一定的代码实现能力。
一、概述
在当今的数字化时代,API&am…
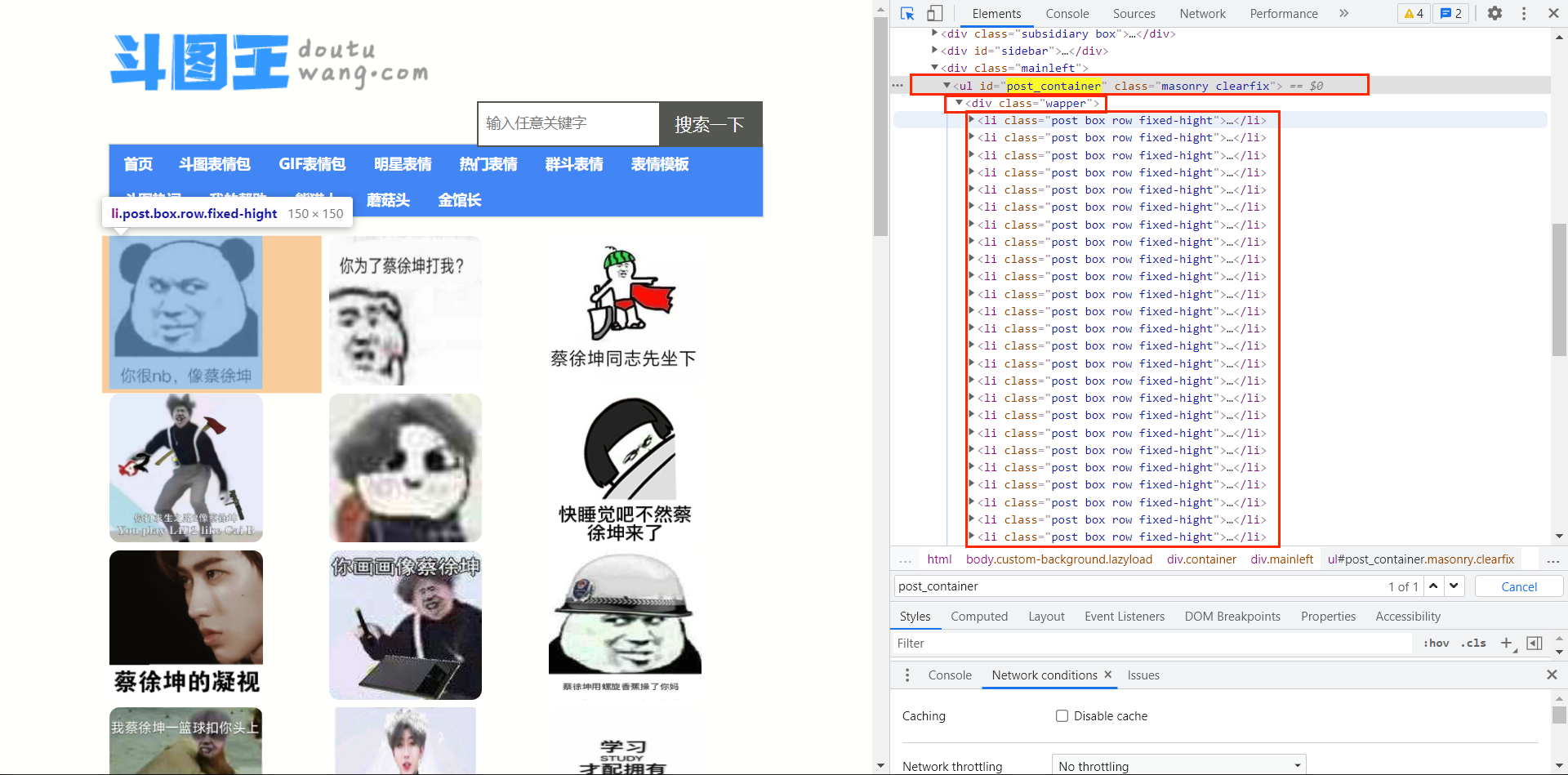
简单Java爬虫案例-HttpClient4.X+Jsoup爬取-ikun-表情包
🐔🐔🐔作为一名真爱粉怎么能没有ikun的表情包?🐔🐔🐔🍓使用到的技术HttpClient4.x 也就是 org.apache.http.xxx 这个版本Jsoup 1.15.3坤图来源:斗图王🍒主要思路借助Htt…

爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上效果图 1、网页分析
(1)准备工作
首先我们使用 Chrome 浏览器打开 百度贴吧,在输入栏中输入关键字进行搜索,这…
爬虫系列(七) requests的基本使用
一、requests 简介
requests 是一个功能强大、简单易用的 HTTP 请求库,可以使用 pip install requests 命令进行安装
下面我们将会介绍 requests 中常用的方法,详细内容请参考 官方文档
二、requests 使用
在开始讲解前,先给大家提供一个…

爬虫系列(八) 用requests实现天气查询
这篇文章我们将使用 requests 调用天气查询接口,实现一个天气查询的小模块,下面先贴上最终的效果图 1、接口分析
虽然现在网络上有很多免费的天气查询接口,但是有很多网站都是需要注册登陆的,过程比较繁琐
几经艰辛,…

爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1、网页分析
(1)翻页
我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析,这里示例为《一出好戏》…

爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上效果图: 1、网页分析
(1)初步分析
原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程中发现…

使用多线程或异步技术提高图片抓取效率
导语
图片抓取是爬虫技术中常见的需求,但是图片抓取的效率受到很多因素的影响,比如网速、网站反爬机制、图片数量和大小等。本文将介绍如何使用多线程或异步技术来提高图片抓取的效率,以及如何使用爬虫代理IP来避免被网站封禁。
概述
多线…

Restclient-cpp库介绍和实际应用:爬取www.sohu.com
概述
Restclient-cpp是一个用C编写的简单而优雅的RESTful客户端库,它可以方便地发送HTTP请求和处理响应。它基于libcurl和jsoncpp,支持GET, POST, PUT, PATCH, DELETE, HEAD等方法,以及自定义HTTP头部,超时设置,代理服…

爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1、网页分析
(1)分析 URL 规律
我们首先使用 Chrome 浏览器打开 豆瓣电影 Top250,很容易可以判断出网站是一个静态网页
然后我…
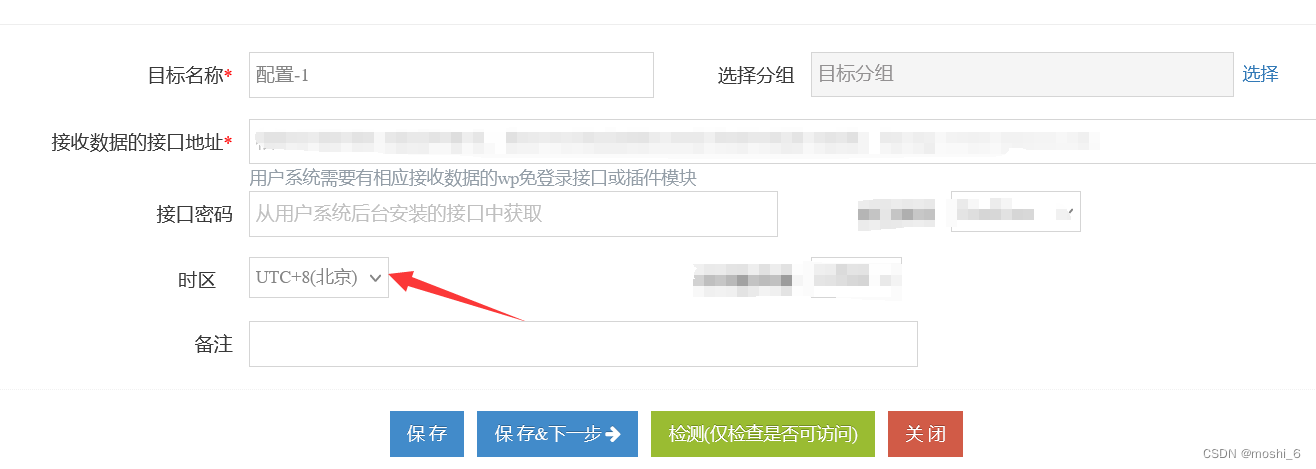
数据发布到WordPress网站,变为已计划、定时或Scheduled
采集数据发布到WordPress网站,但数据没有在前端页面显示,在wordpress后台查看变为已计划、定时或Scheduled。
这个是由于发布的时间变成未来时间导致的,先核实下设置的发布时间是否正确。
如果正确,那就是时区的问题导致时间变成…
Python : Xpath简介及实例讲解
文章目录一、Xpath简介二、Xpath语法规则语法规则标签定位属性定位索引定位取文本内容三、语法规则练习前言CSDN上已经有很多大佬发过Xpath,而且讲的都很好,我是因为刚开始学习网络爬虫,对这些基础重要知识不太了解,所以写一下来加…
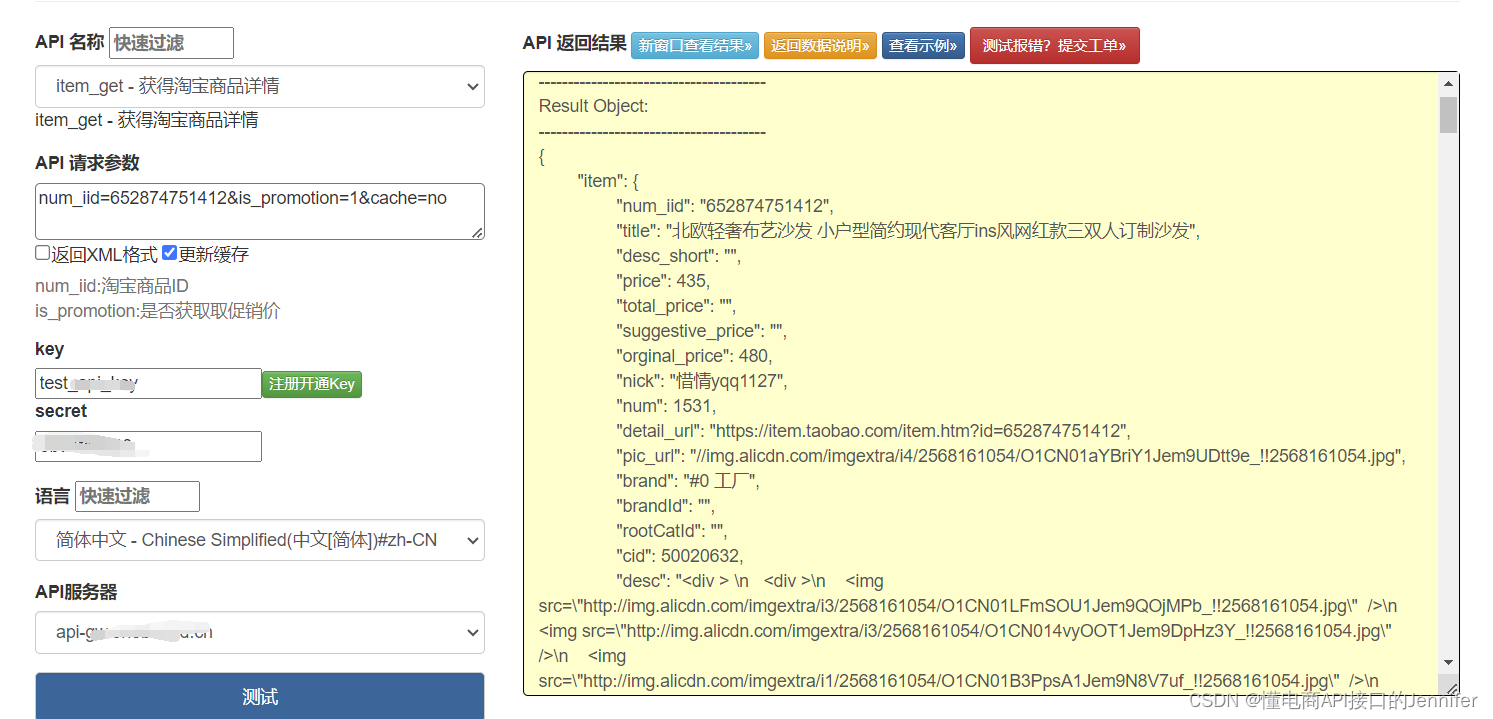
淘宝/天猫获得淘宝商品详情API(含测试示例)
taobao.item_get 调用说明 公共参数
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中进入测试)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等]c…
爬虫系列(五) re的基本使用
1、简介
究竟什么是正则表达式 (Regular Expression) 呢?可以用下面的一句话简单概括:
正则表达式是一组特殊的 字符序列,由一些事先定义好的字符以及这些字符的组合形成,常常用于 匹配字符串
在 Python 中,re 模块…

curl 接口调用工具
后端接口开发完成,你还在为等待前端而无法调试吗?
今天分享一个小工具,curl,一个命令行文件传输工具。可用于大家平常开发的接口调用测试。
它支持文件的上传和下载,支持包括HTTP、HTTPS、ftp等众多协议,…
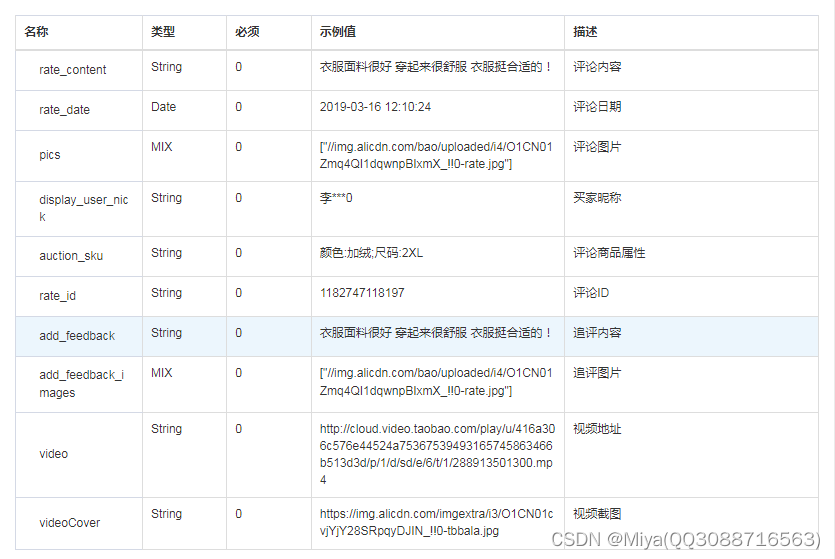
淘宝商品链接获取淘宝商品评论数据(用 Python实现淘宝商品评论信息抓取)
在网页抓取方面,可以使用 Python、Java 等编程语言编写程序,通过模拟 HTTP 请求,获取淘宝多网站上的商品详情页面评论内容。在数据提取方面,可以使用正则表达式、XPath 等方式从 HTML 代码中提取出有用的信息。值得注意的是&#…
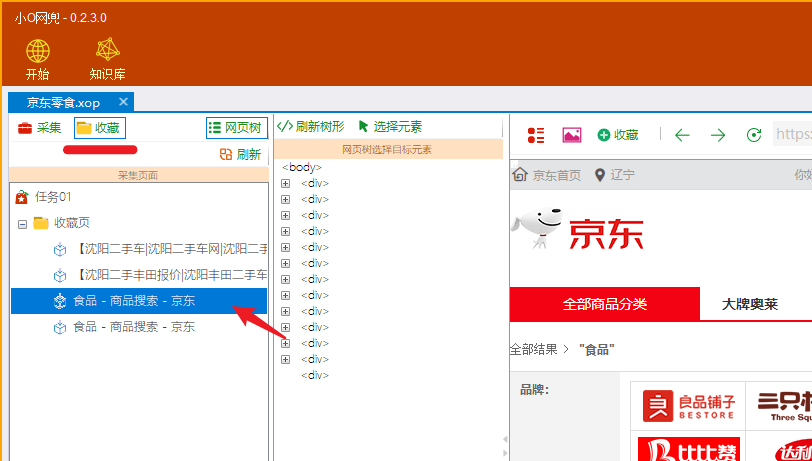
小O网兜0231新版 -- 用户入门指南
本文介绍小O网兜入门功能,通过本文用户能够掌握数据采集的基本操作,使用软件提供的模板任务采集指定页面的数据。
基本概念
任务文件:新建任务文件,扩展名为 xop,任务的配置、采集数据等信息保存在该文件中ÿ…

爬虫实战(三) 用Python爬取拉勾网
0、前言
最近博主面临着选方向的困难(唉,选择困难症患者 >﹏<),所以希望了解一下目前不同岗位的就业前景
这时,就不妨写个小爬虫,爬取一下 拉勾网 的职位数据,并用图形…

爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛
本着 “用技术改变生活” 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序
这篇文章,我们就来讲讲…

4.多线程多进程及多线程爬虫开发
目录
一、进程与线程
1.进程与多进程
2.线程与多线程
3.python中的多线程与多进程
二、多线程库Threading
三、多进程库multiprocessing
1.使用Process类创建进程
2.使用Pool类实现多进程
3.使用dummy.Pool类实现多线程
四、开发多线程爬虫
五、练习 前面我们所讲的…
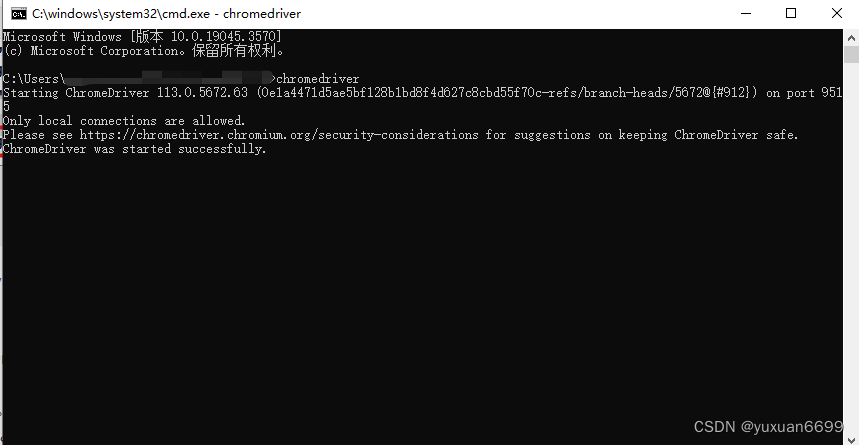
ChromeDriver最新版本下载与安装方法
关于ChromeDriver最新下载地址:https://googlechromelabs.github.io/chrome-for-testing/
下载与安装 setp1:查看Chrome浏览器版本 首先,需要检查Chrome浏览器的版本。请按照以下步骤进行:
打开Chrome浏览器。 点击浏览器右上角…

10.爬虫与数据库—Redis数据库(含爬虫实战)
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API。[1]
因为Reids是基于内存存储的数据库,所以它在读写上速度要MongoDB要快的多的多。
一、Redis环境搭建
1.mac中安装redis brew…
6.HTML内容解析-BeautifulSoup4
目录
一、安装BeautifulSoup4
二、导入 BeautifulSoup4
三、生成BeautifulSoup对象
1.解析器
2.requests与BeautifulSoup结合使用
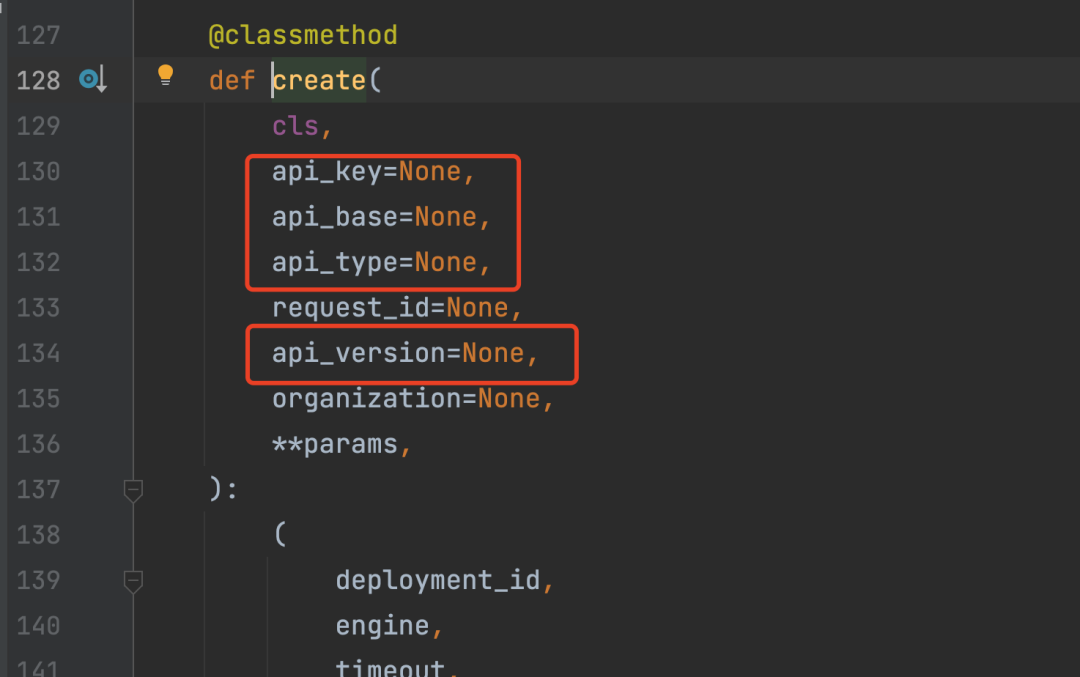
一日一技:Python如何同时调用多个GPT的API?
相信很多同学或多或少都在Python中使用过GPT API,通过Python安装openai库,来调用GPT模型。
OpenAI官方文档中给出了一个示例,如下图所示:
OpenAI API 测试 如果你只有一个API账号,那么你可能不觉得这样写有什么问题。…
快手商品详情API 商品销量API 商品列表API 获取商品价格数据API
item_get-根据ID取商品详情
ks.item_get 测试入口 公共参数
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,ite…

使用Puppeteer进行游戏数据可视化
导语
Puppeteer是一个基于Node.js的库,可以用来控制Chrome或Chromium浏览器,实现网页操作、截图、测试、爬虫等功能。本文将介绍如何使用Puppeteer进行游戏数据的爬取和可视化,以《英雄联盟》为例。
概述
《英雄联盟》是一款由Riot Games开…
Python爬虫之关系型数据库存储#5
关系型数据库是基于关系模型的数据库,而关系模型是通过二维表来保存的,所以它的存储方式就是行列组成的表,每一列是一个字段,每一行是一条记录。表可以看作某个实体的集合,而实体之间存在联系,这就需要表与…
京东获得JD商品详情 API 接口文档(含请求代码)
item_get-获得JD商品详情 API测试工具 注册开通 公共参数
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,item_sea…
【python爬虫】—图片爬取
图片爬取 需求分析Python实现 需求分析
从https://pic.netbian.com/4kfengjing/网站爬取图片,并保存
Python实现
获取待爬取网页
def get_htmls(pageslist(range(2, 5))):"""获取待爬取网页"""pages_list []for page in pages:u…
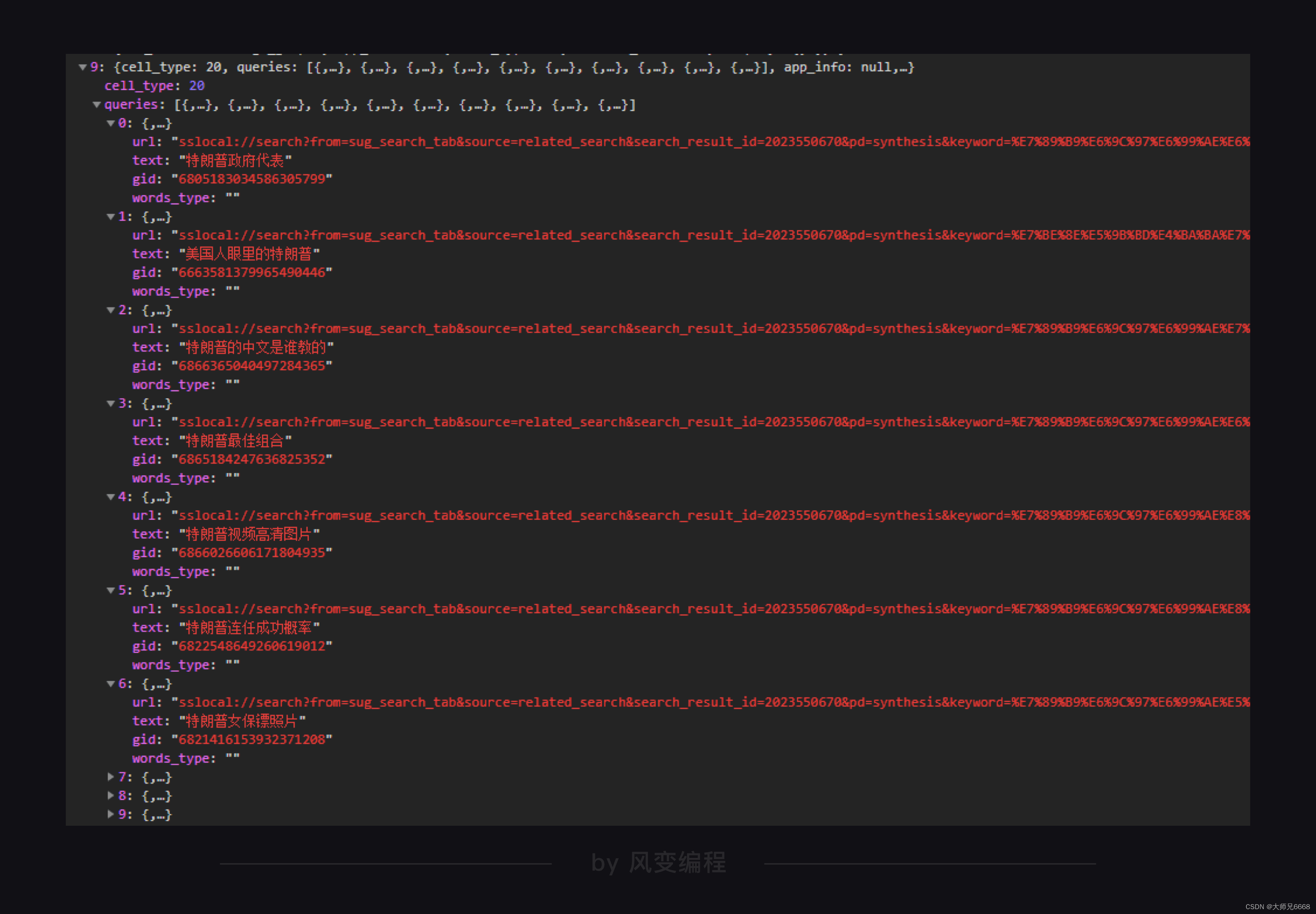
【python爬虫】8.温故而知新
文章目录 前言回顾前路代码实现体验代码功能拆解获取数据解析提取数据存储数据 程序实现与总结 前言
Hello又见面了!上一关我们学习了爬虫数据的存储,并成功将QQ音乐周杰伦歌曲信息的数据存储进了csv文件和excel文件。
学到这里,说明你已经…
【python爬虫】5.爬虫实操(歌词爬取)
文章目录 前言项目:寻找周杰伦分析过程代码实现重新分析过程什么是NetworkNetwork怎么用什么是XHR?XHR怎么请求?json是什么?json数据如何解析?实操:完成代码实现 一个总结一个复习 前言
这关让我们一起来寻…

爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释
我的第一个想法是做一个数据库,把常用的词语和解释放到数据库里面,当用户查询时直接读取数据库结果
但是自己又没有心思做这样一个数据库,于是就…

爬虫系列(一) 网络爬虫简介
写在前面的话 :最近博主在学习网络爬虫的相关技术(基于 Python 语言),作为一个学习的总结,打算用博客记录下来,也希望和大家分享一下自己在学习过程中的点点滴滴,话不多说,让我们马上…

什么是电商API?API有什么作用?电商API的分类有哪些?
随着电子商务的迅猛发展,电商API(应用程序编程接口)已成为连接电商平台与外部应用程序的重要桥梁。通过API,电商平台可以提供一系列功能,使得外部开发者能够利用这些功能来扩展平台的功能,提高用户体验&…

公司可能会用到的内容抓取系统爬虫服务
设计框架结构
对于大型的爬虫系统,保障系统的平稳运行和效率是十分重要的,通常公司会采用微服务架构进行拆分,对每一块业务封装单独的服务,下面根据公司可能使用的业务框架进行分析
BrowserServer:该服务主要作为获…

打造 API 接口的堡垒
前言
伴随互联网革命快速创新发展,API 需求的日益剧增,针对 API 的攻击几乎遍布各个行业,据报道 2022 年全年平均每月遭受攻击的 API 数量超过 21 万,游戏、社交、电商、制造等行业依然是攻击者主要目标。例如社交软件某特&#…

什么是网络爬虫技术?它的重要用途有哪些?
网络爬虫(Web Crawler)是一种自动化的网页浏览程序,能够根据一定的规则和算法,从互联网上抓取和收集数据。网络爬虫技术是随着互联网的发展而逐渐成熟的一种技术,它在搜索引擎、数据挖掘、信息处理等领域发挥着越来越重…

使用采集工具,轻松获取目标受众的数据,让您的市场营销更加精准
【数据采集神器】使用采集工具,轻松获取目标受众的数据,让您的市场营销更加精准!
在当前这个信息化社会中,数据已经成为了企业发展和市场营销的必要手段。企业需要通过数据来了解市场的需求,了解自己产品的竞争优势&a…

猿人学第三题 罗生门
思路
使用开发者工具进行抓包,验证数据请求的方式是什么,这里推荐大家使用浏览器自带的工具。 我们发现每次的翻页请求都会有一个jssm请求,这里我们先记录一下这个情况,现在观察一下cookie是否有变化。 这个实际上没有发生变化。…
淘宝商品评论接口API:获取淘宝商品评论数据评论总数(支持排序)
淘宝/天猫获得淘宝商品评论 API 返回值说明
item_review-获得淘宝商品评论
公共参数
名称类型必须描述keyString是调用key(注册账号获取key)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search…

淘宝卖家如何批量采集竞品sku进行分析?推荐2个商品sku获取API
item_sku-获取sku详细信息
请求参数
请求参数:num_iid572050066584&sku_id3880971359554&is_promotion0
参数说明:sku_id:SKU ID num_iid:商品ID is_promotion:是否获取取促销价
API测试页 获取key&secret 响应参数
Version: Date:
名…
Nutch Lucene 之 搜索引擎文本分析
收获:过去的一年里 —— 自己感觉到最明显的收获,不是金钱,也不是学了几门技术,更不是多看了一本经典书籍,而是自己面对难题,有一颗持之以恒的心,不到最后誓不罢休的精神;此时的我&a…


Python爬取京东商品评论
寻找数据真实接口
打开京东商品网址查看商品评价。我们点击评论翻页,发现网址未发生变化,说明该网页是动态网页。 API名称:item_review-获得JD商品评论
公共参数
获取API测试key&secret
名称类型必须描述keyString是调用keyÿ…
Python爬虫存储库安装
如果你还没有安装好MySQL、MongoDB、Redis 数据库,请参考这篇文章进行安装:
Windows、Linux、Mac数据库的安装(mysql、MongoDB、Redis)-CSDN博客
存储库的安装
上节中,我们介绍了几个数据库的安装方式,但…
Tiktok/抖音旋转验证码识别
一、引言
在数字世界的飞速发展中,安全防护成为了一个不容忽视的课题。Tiktok/抖音,作为全球最大的短视频平台之一,每天都有数以亿计的用户活跃在其平台上。为了保护用户的账号安全,Tiktok/抖音引入了一种名为“旋转验证码”的安…
电商淘宝爬虫API与淘宝官方开放平台API的区别以及如何选择适合自己的API接口
随着数字化时代的到来,数据已经成为企业竞争力的重要因素。为了获取数据,企业或个人常常需要使用API接口。常见的API接口包括爬虫API和官方开放平台API。本文将详细介绍这两种API接口的区别以及如何选择适合自己的API接口。
一、爬虫API与官方开放平台A…

爬虫API|批量抓取电商平台商品数据,支持高并发
随着互联网的快速发展,电商平台如雨后春笋般涌现,为消费者提供了丰富的购物选择。然而,对于许多商家和数据分析师来说,如何快速、准确地获取电商平台上的商品数据成为了一个难题。为了解决这个问题,我们开发了一个爬虫…
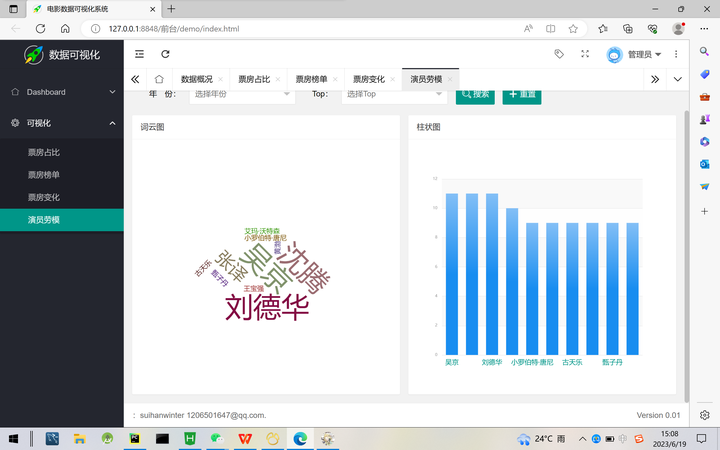
基于Python flask MySQL 猫眼电影可视化系统设计与实现
1 绪论 1.1 设计背景及目的
猫眼电影作为国内知名的电影信息网站,拥有海量的电影信息、票房数据和用户评价数据。这些数据对于电影市场的研究和分析具有重要意义。然而,由于数据的复杂性和数据来源的多样性,如何有效地采集、存储和展示这些数…
![CMS-织梦[dede]-通用免登发布插件](https://img-blog.csdnimg.cn/60bbb02f08e74107a712d21a01b0ac21.png)
CMS-织梦[dede]-通用免登发布插件
CMS-织梦[dede]-通用免登发布插件 1. 织梦通用免登陆发布插件功能说明2. 织梦通用免登陆发布接口使用说明2-1 下载插件2-2 安装插件3 对接火车头等采集工具 3 爬虫【古诗文网】示例[可选]测试火车头入库模型 使用火车头,简数采集器,八爪鱼等文章采集工具…

大数据项目——基于Django/协同过滤算法的房源可视化分析推荐系统的设计与实现
大数据项目——基于Django/协同过滤算法的房源可视化分析推荐系统的设计与实现
技术栈:大数据爬虫/机器学习学习算法/数据分析与挖掘/大数据可视化/Django框架/Mysql数据库
本项目基于 Django框架开发的房屋可视化分析推荐系统。这个系统结合了大数据爬虫、机器学…

996已明确违法,从此拒绝精神内耗!
之前一个禅道用户说,他在国外工作时主动加过两次班,然而被上司慰问了。上司特别严肃地跟他说:“请你不要再加班了,这让我很困扰。我们不加班,而且我无法向我的上司解释你为什么要加班,工作做不完可以明天做…
采用BeautifulSouppqQueryxpath三种方法爬取电影详情页
采用三个框架BeautifulSoup&&pqQuery&&xpath,爬取知名的电影网页
主要是想体验这三种框架爬同一个网页的不同。
当然具体的不同我也说不清道不明 只能是体验了一把
以下代码都是本人亲自撸 如图所示,四个位置。分别爬取 电影名字 -&g…

Larbin——一款c++编写的爬虫程序
Larbin——一款c编写的爬虫程序2009-08-13 22:01今天我读了一篇名叫“开源网络爬虫程序(spider)一览“的文章,然后就在列表的末尾看到了这个程序"Larbin",由于它是唯一一个用c写的,而在所有编程语言中我对于c是最熟悉的…

电商系统中API接口防止参数篡改和重放攻击(小程序/APP)
说明:目前所有的系统架构都是采用前后端分离的系统架构,那么就不可能避免的需要服务对外提供API,那么如何保证对外的API的安全呢?
即生鲜电商中API接口防止参数篡改和重放攻击
目录
1. 什么是API参数篡改?
说明:AP…
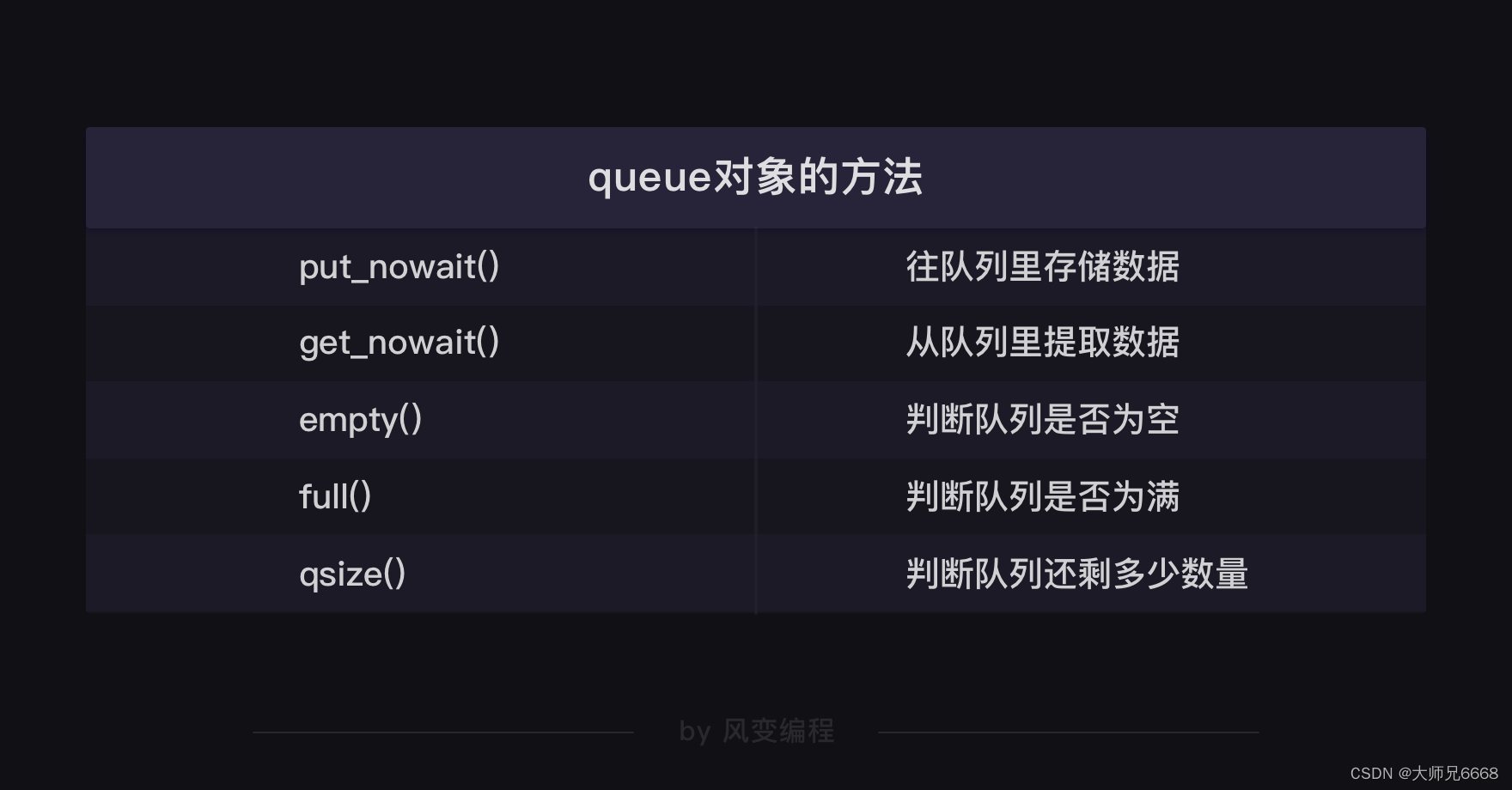
【python爬虫】12.建立你的爬虫大军
文章目录 前言协程是什么多协程的用法gevent库queue模块 拓展复习复习 前言
照旧来回顾上一关的知识点!上一关我们学习如何将爬虫的结果发送邮件,和定时执行爬虫。
关于邮件,它是这样一种流程: 我们要用到的模块是smtplib和emai…

Python爬虫之极验滑动验证码的识别
极验滑动验证码的识别
上节我们了解了可以直接利用 tesserocr 来识别简单的图形验证码。近几年出现了一些新型验证码,其中比较有代表性的就是极验验证码,它需要拖动拼合滑块才可以完成验证,相对图形验证码来说识别难度上升了几个等级。本节将…
【软件安装】Python安装详细教程(附安装包)
软件简介
Python由荷兰数学和计算机科学研究学会的Guido van Rossum 于1990 年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,…

Python如何爬取免费爬虫ip
做过大数据抓取的程序员应该都知道,正常市面上的爬虫ip只分为两种,一种是API提取式的,还有一种是账密形式隧道模式的。往往因为高昂费用而止步。对于初学者觉得没有必要,我们知道每个卖爬虫ip的网站有的提供了免费IP,可…
技术干货 —— 手把手教你通过缓存提升 API 性能
许多开发者都希望能够彻底搞清楚 API 的工作方式,以及如何利用缓存 API 请求来提升业务,但是当这个需求进入实现阶段时,许多人就会发现手头并没有合适的工具和恰当的方法,所以我们今天就为大家做一个全面的讲解:
① 几…
Python爬虫之Splash负载均衡配置
爬虫专栏:http://t.csdnimg.cn/WfCSx
Splash基础:Python爬虫之Splash详解-CSDN博客
用 Splash 做页面抓取时,如果爬取的量非常大,任务非常多,用一个 Splash 服务来处理的话,未免压力太大了,此…
Python爬取网站视频资源
思路: 在界面找到视频对应的html元素位置,观察发现视频的url为https://www.pearvideo.com/video_视频的id,而这个id在html中的href中,所以第一步需要通过xpath捕获到所需要的id
在https://www.pearvideo.com/video_id的页面&…

基于Python的书籍数据采集与可视化分析系统
温馨提示:文末有 CSDN 平台官方提供的学长 Wechat / QQ 名片 :) 1. 项目简介 基于Python的书籍数据采集与可视化分析系统旨在挖掘和分析海量图书数据背后的规律和趋势,为读者、出版商和数据分析师提供更深入的洞察和辅助决策。本系统依托于某瓣庞大的图书…
SOCKS5代理的原理、優勢與應用解析
在網路世界中,我們常常會聽到“代理伺服器”這個詞,而SOCKS5代理正是其中的一個重要類型。那麼,SOCKS5代理是什麼呢?它有哪些優勢和應用場景呢?本文將為你詳細解答。
SOCKS5代理是什麼?
SOCKS5代理是SOCK…

网络爬虫-Requests库主要方法解析
一、Requests库的7个主要方法 其中,request()是 基础方法,其他6个方法都是基于request()的,但最常用的是get() 和 head()
二、request() 13个访问控制参数: 三、get(): 获取某一个url链接的相关资源 四、head() 五、post() 六、…
【python爬虫】13.吃什么不会胖(爬虫实操练习)
文章目录 前言项目实操明确目标分析过程代码实现 前言
吃什么不会胖——这是我前段时间在健身时比较关注的话题。
相信很多人,哪怕不健身,也会和我一样注重饮食的健康,在乎自己每天摄入的食物热量。
不过,生活中应该很少有人会…
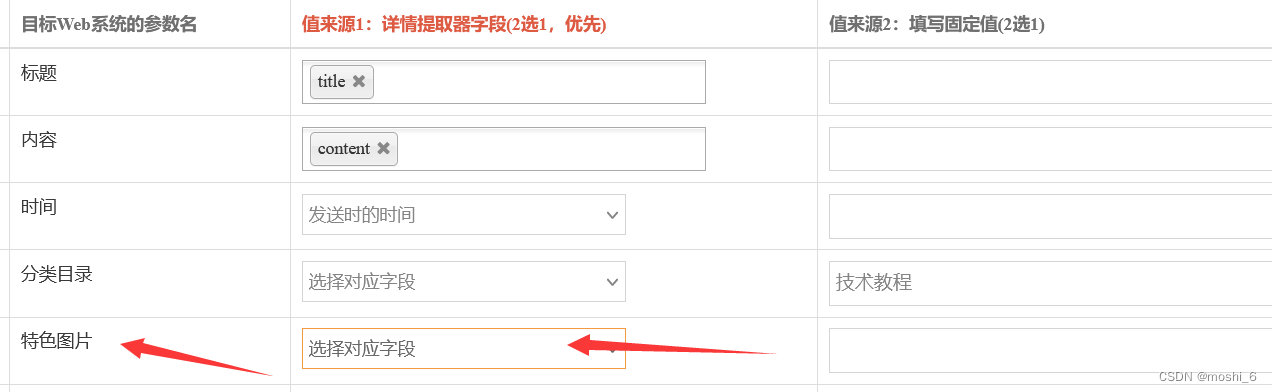
采集发布到WordPress 特色图片(缩略图)无法显示
采集的数据发布到wordpress系统网站,文章内容是正常的,但是在列表页的缩略图(特色图片)却是显示失败。
这种情况有多种问题都可以造成的,可按照以下步骤逐一排查:
目录
1. 发布映射值是否正确
2. 与主题…
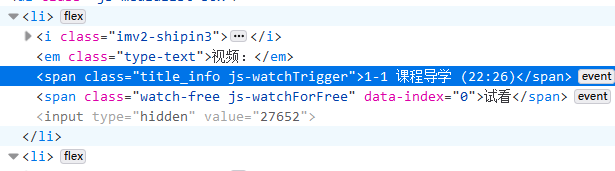
爬虫练习-获取imooc课程目录
代码:
from bs4 import BeautifulSoup
import requests
headers{
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0,
}id371 #课程id
htmlrequests.get(https://coding.imooc.com/class/chapter/id.html#Anchor,head…
【快手API】根据ID取商品详情 API 返回值说明
item_get-根据ID取商品详情
开发背景:
快手是一家中国领先的短视频社交平台,拥有亿级用户规模。为了提升快手平台的商业化能力,快手推出了“快手电商”服务,让商家可以在快手平台上开店、卖货,以及通过快手直播等方式…
淘宝/天猫获取卖出的商品订单列表订单详情 API
seller_order_list-获取卖出的商品订单列表
公共参数
获取请求地址测试key
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search…
如何保证API安全?
前言
最近知识星球中有位小伙伴问了我一个问题:如何保证接口的安全性?
根据我多年的工作经验,这篇文章从11个方面给大家介绍一下保证接口安全的一些小技巧,希望对你会有所帮助。 1 参数校验
保证接口安全的第一步,也…
【Python_Scrapy学习笔记(三)】Scrapy框架之全局配置文件settings.py详解
Scrapy框架之全局配置文件settings.py详解
前言
settings.py 文件是 Scrapy框架下,用来进行全局配置的设置文件,可以进行 User-Agent 、请求头、最大并发数等的设置,本文中介绍 settings.py 文件下的一些常用配置
正文
1、爬虫的项目目录…

采集网页数据保存到文本文件---爬取古诗文网站
访问古诗文网站(https://so.gushiwen.org/mingju/) 会显示出这个页面,里面包含了很多的名句,点击某一个名句(比如点击无处不伤心,轻尘在玉琴)就会出现完整的古诗 我们点击鼠标右键,点…

使用WebMagic 编写 java 网络爬虫
写这个的目的是为了爬歌词,因为喜欢听歌,遇到喜欢的歌就喜欢把歌词下载下来。 WebMacgic 教程地址
http://webmagic.io/docs/zh/posts/ch1-overview/ 使用 IDEA 创建 maven工程 下面为工程目录结构 下面为源代码 package bean;import us.codecraft.webm…

【python爬虫】7.爬到的数据存到哪里?
文章目录 前言存储数据的方式存储数据的基础知识基础知识:Excel写入与读取基础知识:csv写入与读取项目:存储周杰伦的歌曲信息 复习 前言
上一关我们以QQ音乐为例,主要学习了如何带参数地请求数据(get请求)…
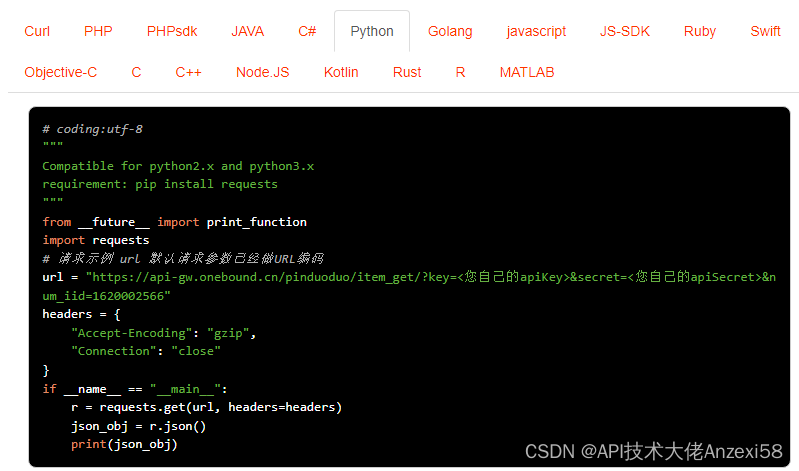
京东商品详情API接口使用方法以及示例代码,可高并发请求
京东商品详情API接口是一种用于获取京东商品详细信息的接口。通过该接口,开发人员可以获取到商品的ID、名称、价格、销量、评价等信息,从而进行进一步的数据分析和应用开发。本文将介绍京东商品详情API接口的使用方法、注意事项以及示例代码。
一、使用…
数学之美 系列十三 信息指纹及其应用
信息指纹及其应用
吴军,Google 研究员 任何一段信息文字,都可以对应一个不太长的随机数,作为区别它和其它信息的指纹(Fingerprint)。只要算法设计的好,任何两段信息的指纹都很难重复,就如同人类的指纹一样…

3.简单的网页爬虫开发
目录
一、爬虫开发中的法律与道德问题
1.数据采集的法律问题
(1)妨害个人信息安全
(2)涉及国家安全信息
(3)妨害网站正常运行
(4)侵害他人利益
(5)内幕…

使用C#和HtmlAgilityPack打造强大的Snapchat视频爬虫
概述
Snapchat作为一款备受欢迎的社交媒体应用,允许用户分享照片和视频。然而,由于其特有的内容自动消失特性,爬虫开发面临一些挑战。本文将详细介绍如何巧妙运用C#和HtmlAgilityPack库,构建一个高效的Snapchat视频爬虫。该爬虫能…
Python爬虫的基本原理
我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样…
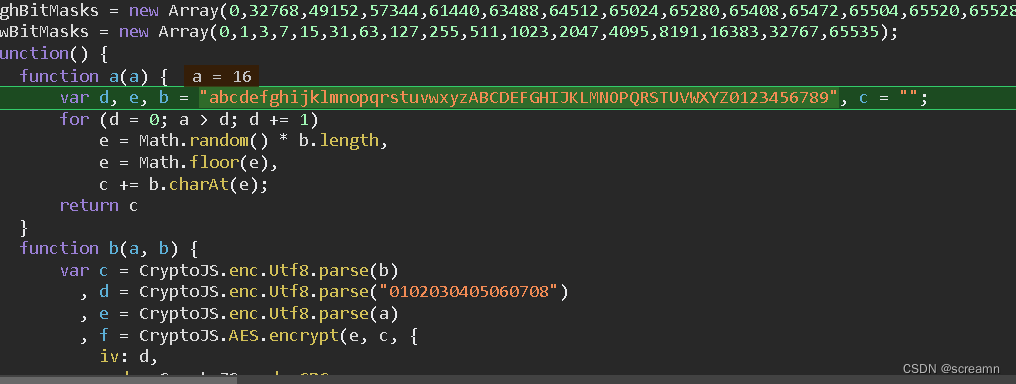
逆向获取某音乐软件的加密(js逆向)
本文仅用于技术交流,不得以危害或者是侵犯他人利益为目的使用文中介绍的代码模块,若有侵权请联系作者更改。
老套路,打开开发者工具,直接开始找到需要的数据位置,然后观察参数,请求头,cookie是…

【python爬虫】14.Scrapy框架讲解
文章目录 前言Scrapy是什么Scrapy的结构Scrapy的工作原理 Scrapy的用法明确目标与分析过程代码实现——创建项目代码实现——编辑爬虫代码实现——定义数据代码实操——设置代码实操——运行 复习 前言
前两关,我们学习了能提升爬虫速度的进阶知识——协程…
MIT 6.824 练习1
Hi, there! 这是一份根据 MIT 6.824(2021) 课程的第 2 课的课堂示例代码改编的 2 个 go 语言编程练习。像其他的编程作业一样,我去除了核心部分,保留了代码框架,并编写了每一步的提示
练习代码在本文的最后面
爬虫
在第一部分,…
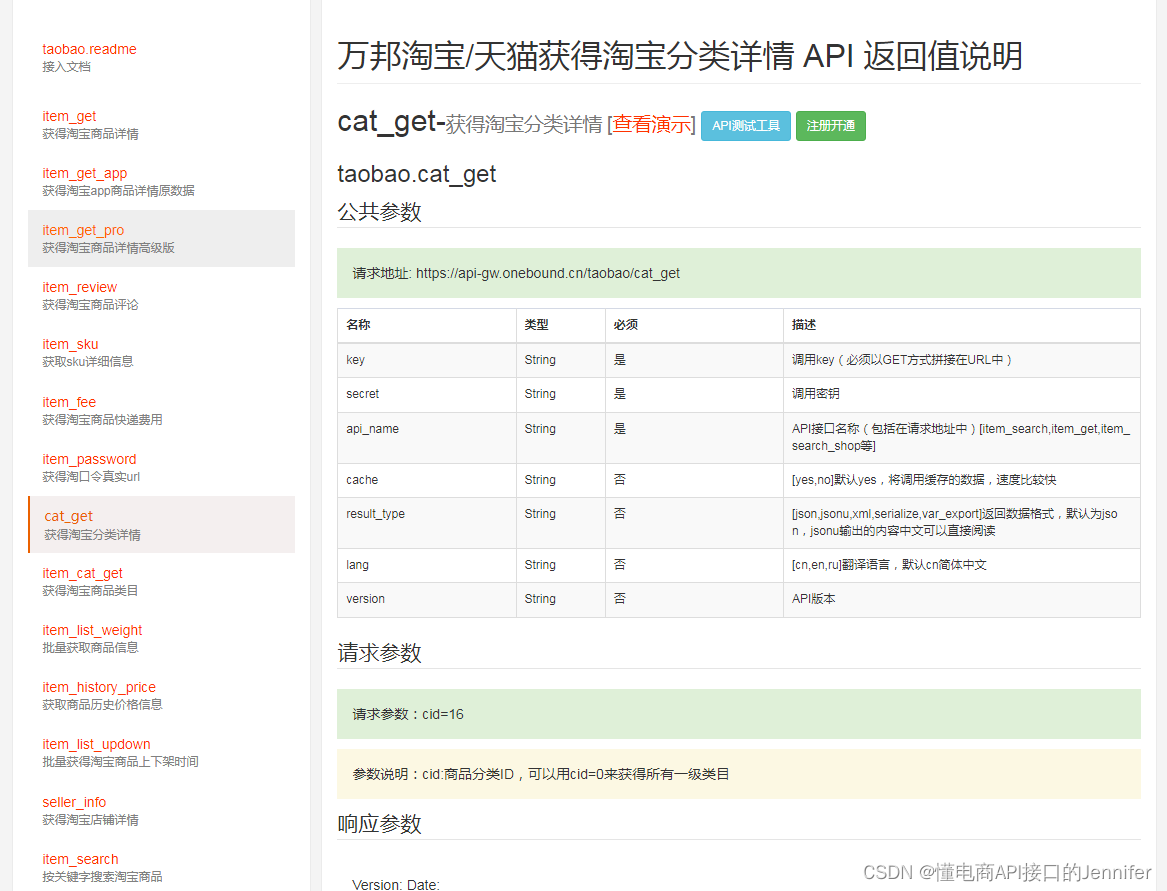
获取淘宝商品分类详情API,抓取淘宝全品类目API接口分享(代码展示、参数说明)
商品分类技巧
淘宝店铺分类怎么设置?我们登录卖家账号的时候,我们看到自己的商品,会想要给商品进行分类,一个好的分类可以帮助提高商品的曝光率。那么在给商品分类前,如果您毫无头绪,以下几点可以给您带来…
1688拍立淘接口 按图搜索1688商品列表
item_get-获得1688商品详情
1688.item_get接入测试 公共参数
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,item…
Python爬虫之文件存储#5
爬虫专栏:http://t.csdnimg.cn/WfCSx
文件存储形式多种多样,比如可以保存成 TXT 纯文本形式,也可以保存为 JSON 格式、CSV 格式等,本节就来了解一下文本文件的存储方式。
TXT 文本存储
将数据保存到 TXT 文本的操作非常简单&am…
虾皮商品采集商品详情API接口
API具体是啥?
API是应用程序编程接口(Application Programming Interface)的缩写。它是一组定义了软件组件之间交互的规范和方法的集合。API允许不同的软件系统之间进行通信和交互,使它们能够相互访问和共享功能、数据和服务。
…
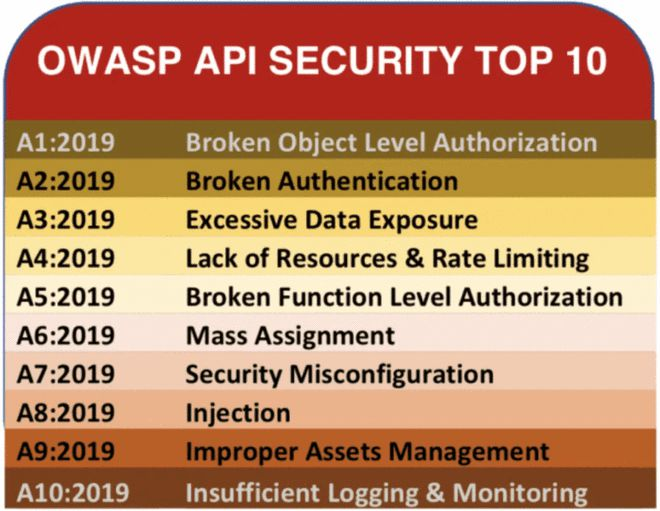
走进API,了解数字化转型时代应用新宠
现今,国家正全面推进各行业数字化转型进程,“十四五”规划和2035年远景目标纲要明确提出“加快数字化发展”“建设数字中国”要求。近年来,随着数字化时代的来临,加之疫情的催生,已有越来越多的企业投入到数字化转型的…
API分享:淘宝拍立淘API接口|按图搜索商品列表API|电商爆品搜索API
今天来跟大家分享一个非常有用的API,以图搜索商品列表API:item_search_img。通过此API可以实现传入一个图片链接,来获取到该图片上的商品信息,商品列表,支持翻页展示。
item_search_img-按图搜索淘宝商品(…
20行Python代码爬取拼多多商品详情数据api
拼多多根据ID取商品详情 API
pinduoduo.item_get 获取商品详情
pinduoduo.item_get_app 获取app商品详情
公共参数
请求地址: https://api-TEST.cn/pinduoduo/item_get_app
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretStr…
案例--某站视频爬取
众所周知,某站的视频是: 由视频和音频分开的。 所以我们进行获取,需要分别获得它的音频和视频数据,然后进行音视频合并。 这么多年了,某站还是老样子,只要加个防盗链就能绕过。(防止403…

【爬虫】专栏文章索引
为了方便 快速定位 和 便于文章间的相互引用等 作为一个快速准确的导航工具
爬虫 目录:
(一)web自动化和接口自动化
(二)实战-爬取Boss直聘信息数据
API安全之《大话:API的前世今生》
写在前面:本文结合API使用的业界现状,系统性地阐述API的基本概念、发展历史、表现形式等基础内容,主要包含以下内容:
1.什么是API
2.API的发展历史
3.现代API常用消息格式
4.top N 互联网企业API 使用现状 当前的世界是一个信…
【学习心得】网络中常见数据格式(爬虫入门知识)
在爬虫爬取数据的之前,必须先系统的了解一下我们待爬取的数据有哪些格式,这样做的好处在与能针对不同的数据类型采取不同分方法手段。 一、XML XML(Extensible Markup Language)是一种可扩展的标记语言,它定义了一套标…

Python爬虫之图形验证码的识别
爬虫专栏:http://t.csdnimg.cn/WfCSx
前言
目前,许多网站采取各种各样的措施来反爬虫,其中一个措施便是使用验证码。随着技术的发展,验证码的花样越来越多。验证码最初是几个数字组合的简单的图形验证码,后来加入了英…

快乐学Python,使用爬虫爬取电视剧信息,构建评分数据集
在前面几篇文章中,我们了解了Python爬虫技术的三个基础环节:下载网页、提取数据以及保存数据。
这一篇文章,我们通过实际操作来将三个环节串联起来,以国产电视剧为例,构建我们的电视剧评分数据集。
1、需求描述
收集…

Android网络爬虫程序(基于Jsoup)
摘要:基于 Jsoup 实现一个 Android 的网络爬虫程序,抓取网页的内容并显示出来。写这个程序的主要目的是抓取海投网的宣讲会信息(公司、时间、地点)并在移动端显示,这样就可以随时随地的浏览在学校举办的宣讲会信息了。…

高效拓客必备工具:采集工具助力,让你事半功倍
在当今竞争激烈的市场环境下,企业想要获得更多的市场份额,拓展更多的客户,必须要进行拓客工作。而在拓客过程中,采集工具是必不可少的工具之一。采集工具可以帮助企业快速获取目标客户的信息,并进行有效的沟通和跟进&a…

Puppeteer结合测试工具jest使用(四)
Puppeteer结合测试工具jest使用(四) Puppeteer结合测试工具jest使用(四)一、简介二、与jest结合使用,集成到常规测试三、支持其他的几种四、总结 一、简介 Puppeteer是一个提供自动化控制Chrome或Chromium浏览器的Node…
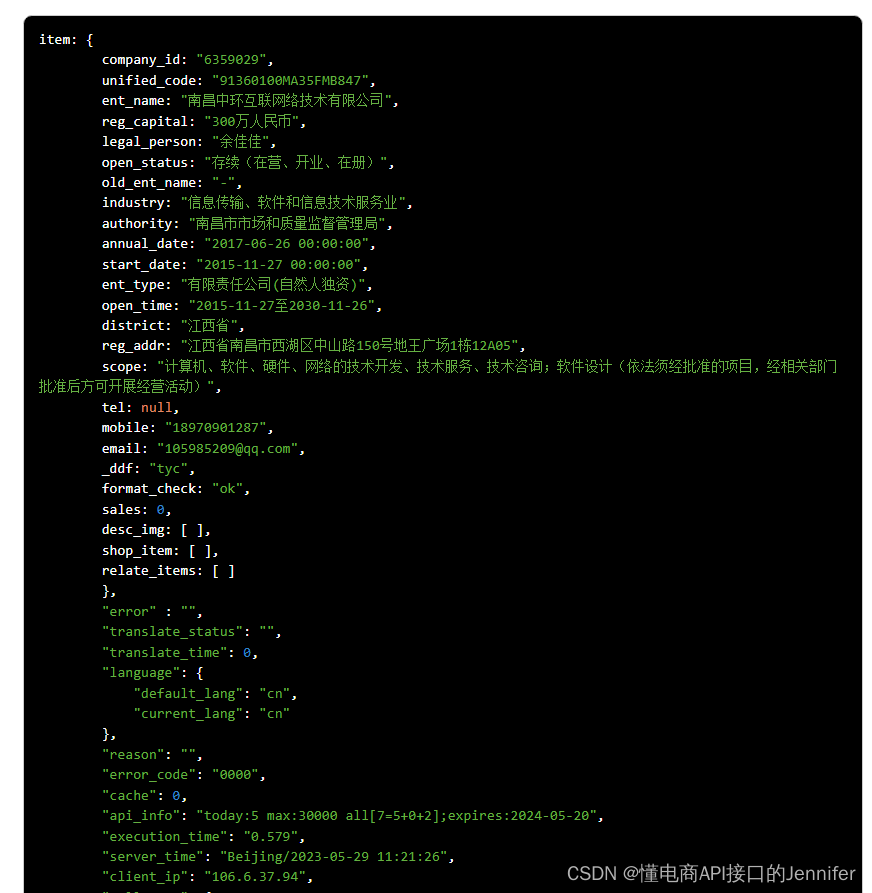
天眼查接口 查询企业信息API 企查查接口
item_get-获得tyc详情
tyc.item_get 公共参数
请求地址: https://api-gw.cn/tyc/item_get
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中࿰…
30万以上的qps高并发服务如何优化
如何优化高并发服务,这里指的是qps在30万以上的在线服务,注意不是离线服务,在线服务会存在哪些挑战呢?
①无法做离线缓存,所有的数据都是实时读的
②大量的请求会打到线上服务,对于服务的响应时间要求较高,一般都是限制要求在300ms以内,如果超过这个时间那么对用户…
网络爬虫之Requests库详解(含多个案例)
网络爬虫是一种程序,它的主要目的是将互联网上的网页下载到本地并提取出相关数据。网络爬虫可以自动化的浏览网络中的信息,然后根据我们制定的规则下载和提取信息。
网络爬虫应用场景:搜索引擎、抓取商业数据、舆情分析、自动化任务。
HTTP…
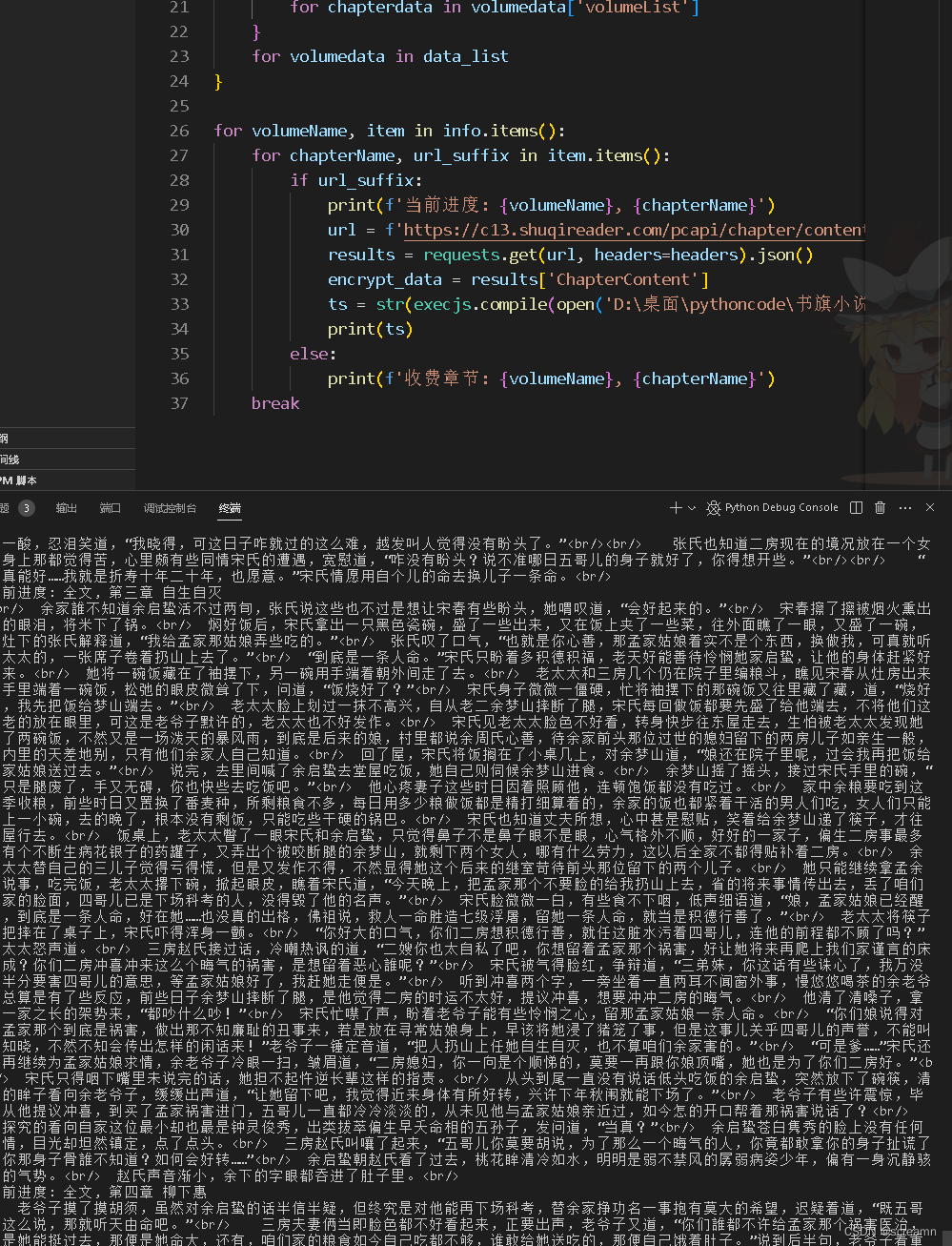
js逆向获取小说数据
本文仅用于技术交流,不得以危害或者是侵犯他人利益为目的使用文中介绍的代码模块,若有侵权请练习作者更改。
网站链接:
aHR0cHM6Ly93d3cuc2h1cWkuY29tLw
分析加密
开始的时候直接进入小说正文,打开抓包工具,直接进行检索。我们…
网络爬虫之BeautifulSoup详解(含多个案例)
在网络爬虫之Requests库详解文章中,我们可以很方便的获取网页内容即网页源代码,但通常我们所需要的只是里面的部分数据,这时就需要对网页内容进行解析,从而提取出有意义的数据。比较常见的方法有正则表达式、HTML或XML解析库等。本…
淘宝买家添加购物车API分享(含请求示例、参数说明)
淘宝添加购物车商品API是为了方便商家在其自己的系统中实现淘宝购物车功能而推出的一种接口。通过接口,商家可以将商品添加至客户的购物车中,并实现订单提交、支付等功能。
一、应用业务场景
添加购物车商品API其应用场景主要是为中小规模的电商商家量…
如何正确选择爬虫采集接口和API?区别在哪里?
在信息时代,数据已经成为了一个国家、一个企业、一个个人最宝贵的资源。而爬虫采集接口则是获取这些数据的重要手段之一。本文将从以下八个方面进行详细讨论:
1.什么是爬虫采集接口?
2.爬虫采集接口的作用和意义是什么?
3.爬虫…
老Python程序员职业生涯感悟—写给正在迷茫的你
我来讲几个极其重要,但是大多数Python小白都在一直犯的思维错误吧!如果你能早点了解清楚这些,会改变你的一生的。所以这一期专门总结了大家问的最多的,关于学习Python相关的问题来给大家聊。希望能带给大家不一样的参考。或者能提…
基于python的网络爬虫
基于python的网络爬虫,爬取新闻网站内容。
import re
import time
from html.parser import HTMLParser
from urllib import requestclass MyHTMLParser(HTMLParser):def handle_data(self, data): #html里的内容data str(data).strip()if (data.__len__() 0):ret…

Python实战笔记(五) 手写一个简单搜索引擎
这篇文章,我们将会尝试从零搭建一个简单的新闻搜索引擎
当然,一个完整的搜索引擎十分复杂,这里我们只介绍其中最为核心的几个模块 分别是数据模块、排序模块和搜索模块,下面我们会逐一讲解,这里先从宏观上看一下它们之…
【Shopee】Open API 申请资格说明 | ERP
一、Open API开放平台说明
为了给开发者提供更好的使用环境,Shopee准备了许多API方便Shopee卖家用户串接。
在Open API平台上,您可以直接申请串接所需之Pantner ID和密钥,无须再逐一向Shopee申请店铺的独立密钥。
此平台提供内容如下&…

用电商API接口获取拼多多的商品详情数据
pinduoduo.item_get_app_pro-根据ID取商品详情原数据
公共参数
API请求地址
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_searc…
Python Selenium 爬虫淘宝案例
爬虫专栏:http://t.csdnimg.cn/WfCSx
前言
在前一章中,我们已经成功尝试分析 Ajax 来抓取相关数据,但是并不是所有页面都可以通过分析 Ajax 来完成抓取。比如,淘宝,它的整个页面数据确实也是通过 Ajax 获取的&#x…
淘宝以图搜商品API调用详细步骤(apiKeysecret)
以图片来搜索商品是电商平台常见的一个功能,一般用于搜索同款、找爆品、淘宝拍立淘等功能。
通过item_search_img可以实现通过图片来搜索同款商品列表,响应参数包括宝贝标题、列表类型、宝贝图片、优惠价、价格、销量、宝贝ID、商品风格标识ID、掌柜昵称…

在C#下运行Python:IronPython和Pythonnet
在C#下运行Python可能有不同的原因。其中一些原因包括:
使用C#应用程序中不可用的特定Python功能或库。结合Python的简单性和表现力以及C#的性能和稳健性,完成不同任务。与基于Python的系统或服务进行集成。
为实现Python和C#之间的互操作性࿰…
多进程爬虫实战-摩托车网
前言 最近有遇到很多私信让我讲一讲多进程的爬虫,我发现大家对爬虫的框架写法和进程的理解有很多的问题和疑问,这次就带来一个小实战让大家理解多进程爬虫以及框架的写法 由于进程爬虫会对任何服务器都有一定的影响,本文仅供学习交流使用&…
python爬虫:JavaScript 混淆、逆向技术
Python爬虫在面对JavaScript混淆和逆向技术时可能会遇到一些挑战,因为JavaScript混淆技术和逆向技术可以有效地阻止爬虫对网站内容的正常抓取。以下是一些应对这些挑战的方法:
分析网页源代码:首先,尝试分析网页的源代码…

电商接口api数据比价接口推荐
当前,受诸多因素的影响,经济下行,在日趋激烈的市场竞争中,很多企业也都面临着越来越大的生存压力,企业的盈利空间也逐渐被压缩。因此,越来越多的企业在控制成本方面更下功夫,这也就对企业采购提…
跨境电商用什么商品采集工具?
跨境电商的商品采集工具和虾皮商品详情接口/搜索接口是电商运营中非常重要的技术工具。本文将详细介绍这两个方面的工具和技术,为跨境电商从业者提供实用的参考。
一、跨境电商商品采集工具
跨境电商的商品采集工具主要用于从多个电商平台采集商品信息,…

Requests-翻页请求实现
翻页请求实现
继https://blog.csdn.net/ssslq/article/details/130747686之后,本篇详述在获取了页面第一页之后,如何获取剩余页的标题内容。 网页:https://books.toscrape.com
找规律
同样还是进行页面的检查,切到网络一栏&…

使用Puppeteer构建博客内容的自动标签生成器
导语
标签是一种用于描述和分类博客内容的元数据,它可以帮助读者快速找到感兴趣的主题,也可以提高博客的搜索引擎优化(SEO)。然而,手动为每篇博客文章添加合适的标签是一件费时费力的工作,有时候也容易遗漏…
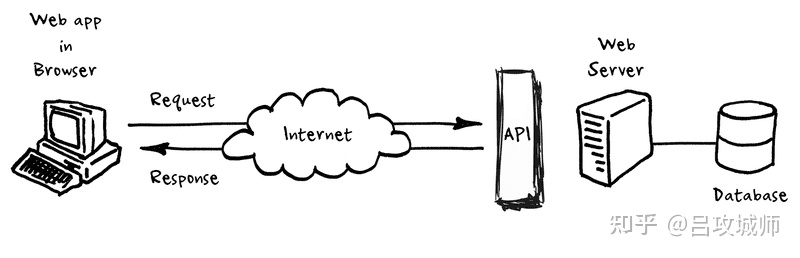
API是什么: 一篇讲透API
在之前一篇文章中,我们深入地讲了如何设计API。然而直到写到很后面,我才意识到我还没有认真地讲过到底API到底是什么。
与1000个读者有1000个哈姆雷特类似,即使你让一个经验非常丰富的程序员给API一个定义,大概率他也会用一个例子…

猿人学刷题系列(第一届比赛)——第二题( js 混淆 - 动态cookie 1)
题目:提取全部5页发布日热度的值,计算所有值的加和
地址:https://match.yuanrenxue.cn/match/2
思路分析
本题我们会简单说一下两种不同的方式去处理,一种是不还原混淆代码直接从源代码硬扣生成逻辑,另一种则是还原…

安卓逆向 - Frida Hook(抓包实践)
一、引言
上篇文章:安卓逆向 - 基础入门教程_小馒头yy的博客-CSDN博客 介绍了Frida的安装、基本使用,今天我们来看看Frida常用Hook和基于Frida抓包实践。
二、Frida常用 Hook脚本
1、hook java.net.URL
function hook1() {var URL Java.use(java.n…
手把手教你使用 Python 调用电商API
Python是一门广泛应用于数据分析、网络爬虫和自动化任务的编程语言。随着电商行业的蓬勃发展,越来越多的开发者需要使用Python来调用电商API来获取商品信息、下单、查询订单等操作。本篇文章将介绍如何利用Python调用电商API,并通过实例详细教你如何进行…

Java 中如何优雅的实现对外接口,需要注意哪些事项?
博主之前做过恒丰银行代收付系统(相当于支付接口),包括现在的oltpapi交易接口和虚拟业务的对外提供数据接口。总之,当你做了很多项目写了很多代码的时候,就需要回过头来,多总结总结,这样你会看到…

简明指南:使用Kotlin和Fuel库构建JD.com爬虫
概述
爬虫,作为一种自动化从网络上抓取数据的程序,广泛应用于数据分析、信息提取以及竞争对手监控等领域。不同的实现方式和编程语言都能构建出高效的爬虫工具。在本文中,我们将深入介绍如何充分利用Kotlin和Fuel库,构建一个简单…
php如何爬取天猫和淘宝商品数据
这篇文章主要介绍了php如何爬取天猫和淘宝商品数据,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
一、思路
最近做了一个网站用到了从网址爬取天猫和淘宝的商…
我和chartGPT的N次对话分享(免费获取)
1、我:做竞品分析如何获取电商平台的商品数据
小凡AI:要获取电商平台的商品数据进行竞品分析,可以采用以下几种方法: 1. 通过爬虫技术获取:使用Python等编程语言编写爬虫程序,模拟用户在电商平台的操作&am…
京东商品链接获取京东商品评论数据(用 Python实现京东商品评论信息抓取),京东商品评论API接口,京东API接口
在网页抓取方面,可以使用 Python、Java 等编程语言编写程序,通过模拟 HTTP 请求,获取京东多网站上的商品详情页面评论内容。在数据提取方面,可以使用正则表达式、XPath 等方式从 HTML 代码中提取出有用的信息。值得注意的是&#…

11.Scrapy框架基础-使用Scrapy抓取数据并保存到mongodb
目录
一、Scrapy安装
1.mac系统
2.windows系统
二、使用scrapy爬取数据
1.新建一个scrapy工程
2.在spiders下新建一个爬虫文件
3.提取网页数据
三、保存数据到mongodb
四、再多学一点
1.添加请求头
2.Robot.txt设置
3.爬取多个页面
五、作业(这是一个考…

Centzy:坑爹的店铺必滚蛋
仅25%的美国本土商业拥有自家的网页,但是会把自家的报价放到网站上更加少得可怜,才10%。Centzy是一个根据价格、营业时间和质量而排序的商业搜索引擎。通过它用户可以快速找到最物美价廉的店铺和服务。 Centzy使用的是自建的众包平台,用户可以…
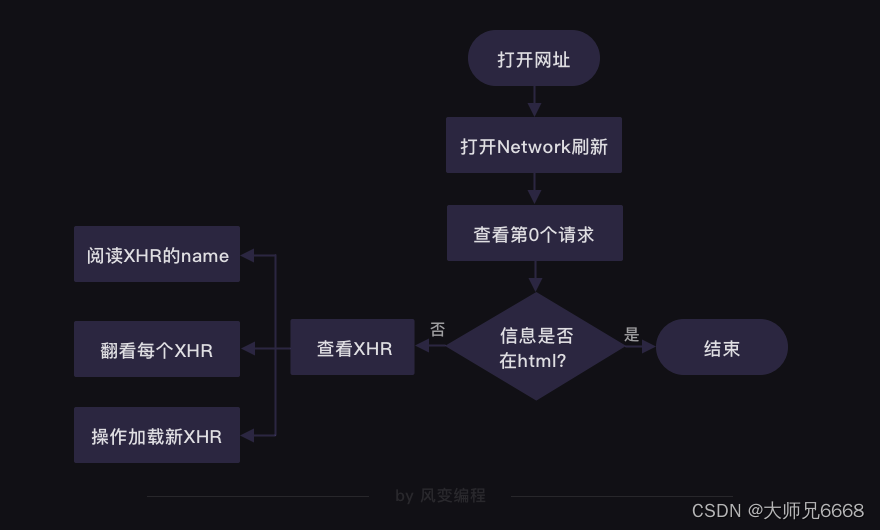
【python爬虫】6.爬虫实操(带参数请求数据)
文章目录 前言项目:狂热粉丝分析过程什么是带参数请求数据如何带参数请求数据 代码实现被隐藏的歌曲清单什么是Request Headers如何添加Request Headers 复习 前言
先来复习一下上一关的主要知识吧,先热个身。
Network能够记录浏览器的所有请求。我们最…
拼多多商品价格监控自动化API接口获取拼多多商品详情数据API接口
随着电子商务的飞速发展,越来越多的人选择在网上购物。在这个充满竞争的市场中,拼多多以其独特的商业模式和创新的营销手段,迅速崛起成为中国领先的电商平台之一。为了更好地满足消费者的需求,拼多多提供了丰富的API接口ÿ…
游戏行业洞察:分布式开源爬虫项目在数据采集与分析中的应用案例介绍
前言
我在领导一个为游戏行业巨头提供数据采集服务的项目中,我们面临着实时数据需求和大规模数据处理的挑战。我们构建了一个基于开源分布式爬虫技术的自动化平台,实现了高效、准确的数据采集。通过自然语言处理技术,我们确保了数据的质量和…
Node.js在Python中的应用实例解析
随着互联网的发展,数据爬取成为了获取信息的重要手段。本文将以豆瓣网为案例,通过技术问答的方式,介绍如何使用Node.js在Python中实现数据爬取,并提供详细的实现代码过程。 Node.js是一个基于Chrome V8引擎的JavaScript运行时环境…
天气预报爬虫-多城市-更新版
以下是直接保存到数据库版本的
import pandas as pd
from bs4 import BeautifulSoup
import re
import time
import requests
import pymysql
import datetime#请求页面方法
def getPage(url):#设置请求头headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Ap…
爬虫API中的滑块验证及解决方案
滑块验证是一种常见的网页验证码机制,用于防止自动化爬取和恶意攻击。在爬虫API中,滑块验证是一种比较常见的反爬措施。下面我们将详细介绍滑块验证的原理、破解方法以及在爬虫API中的应对策略。
一、滑块验证原理
滑块验证是一种基于图像识别的验证码…
批量自动化获取电商平台数据的实现方式有哪些?
随着电子商务的迅猛发展,电商平台的数据日益丰富和多样化。对于许多企业和个人而言,这些数据具有重要的商业价值。因此,如何批量自动化地获取电商平台数据成为了一个热门话题。本文将探讨批量自动化获取电商平台数据的实现方式,并…
淘宝/天猫获取商品历史价格信息 API 返回值说明
淘宝/天猫获取商品历史价格信息 API 返回值说明
item_history_price-获取商品历史价格信息 注册开通
taobao.item_history_price 公共参数
请求地址: https://api-gw.onebound.cn/taobao/item_history_price
名称类型必须描述keyString是调用key(必须以GET方式…
Python爬虫 pyquery库详解#4
爬虫专栏:http://t.csdnimg.cn/WfCSx
使用 pyquery
在上一节中,我们介绍了 Beautiful Soup 的用法,它是一个非常强大的网页解析库,你是否觉得它的一些方法用起来有点不适应?有没有觉得它的 CSS 选择器的功能没有那么…

网络爬虫代理ip有什么好处?爬虫工作使用代理IP有哪些优势?
在爬虫工作中,使用代理IP有很多好处,可以帮助爬虫程序更加高效地完成任务。以下是使用代理IP的几个优势: 1. 增加匿名性 使用代理IP可以隐藏爬虫程序的真正IP地址,增加匿名性,避免被目标网站封禁。通过代理IPÿ…
京东上货软件必备API(商品主图价格详情批量下载上传)
一、引言
在数字化快速发展的今天,电商平台的商品信息管理变得尤为重要。本文将重点介绍京东上货软件必备的API接口,帮助你实现商品主图、价格、详情的批量下载与上传,提高商品管理效率,优化用户体验。
二、京东上货软件必备API…

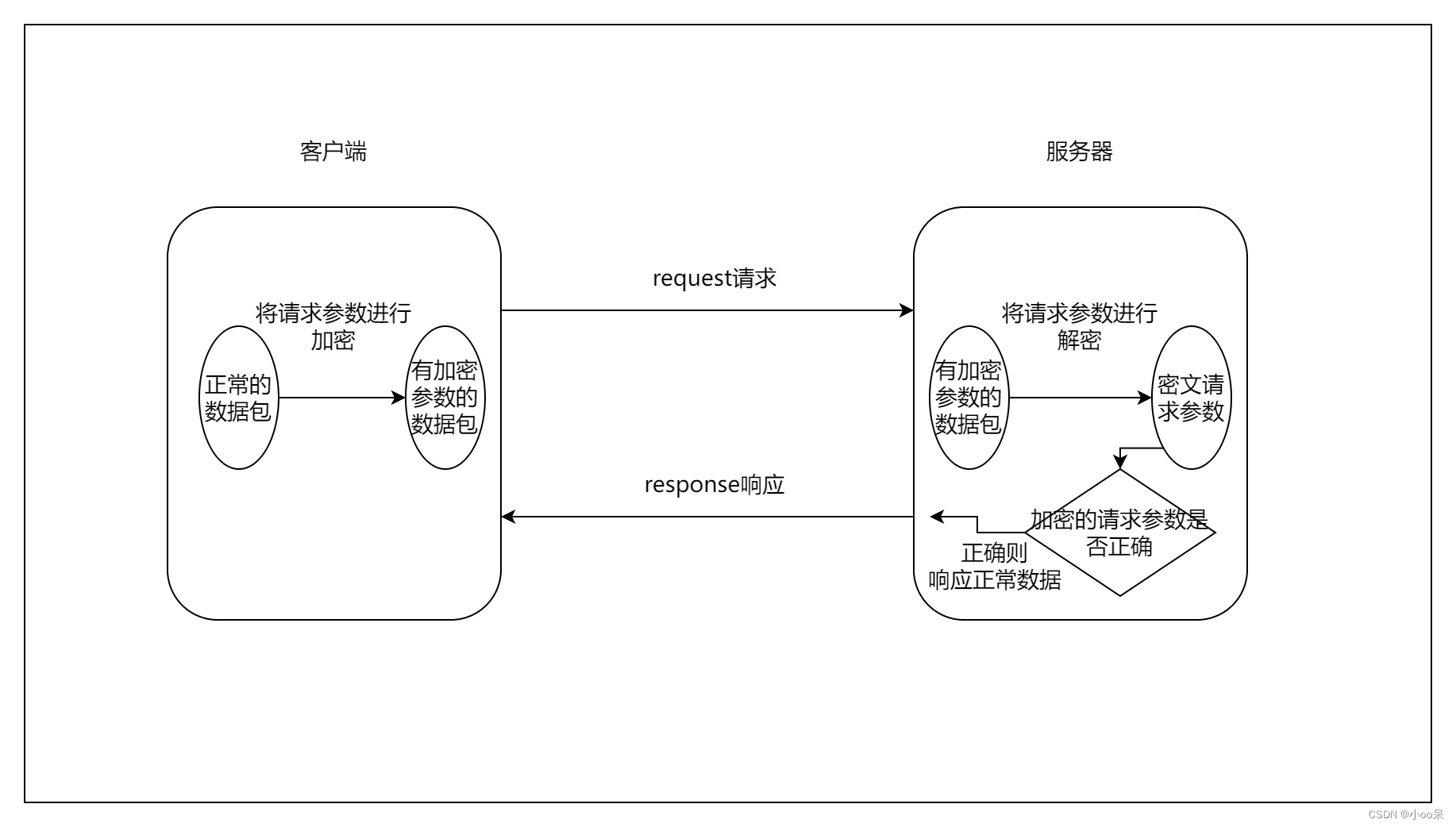
【学习心得】请求参数加密的原理与逆向思路
一、什么是请求参数加密? 请求参数加密是JS逆向反爬手段中的一种。它是指客户端(浏览器)执行JS代码,生成相应的加密参数。并带着加密后的参数请求服务器,得到正常的数据。 常见的被加密的请求参数sign 它的原理和过程图…
利用正则表达式进行爬取数据以及正则表达式的一些使用方法
1.8 本地数据爬取
Pattern:表示正则表达式 Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取。 在大串中去找符合匹配规则的子串。
代码示例:
package com.itheima.a08regexdemo;
import …
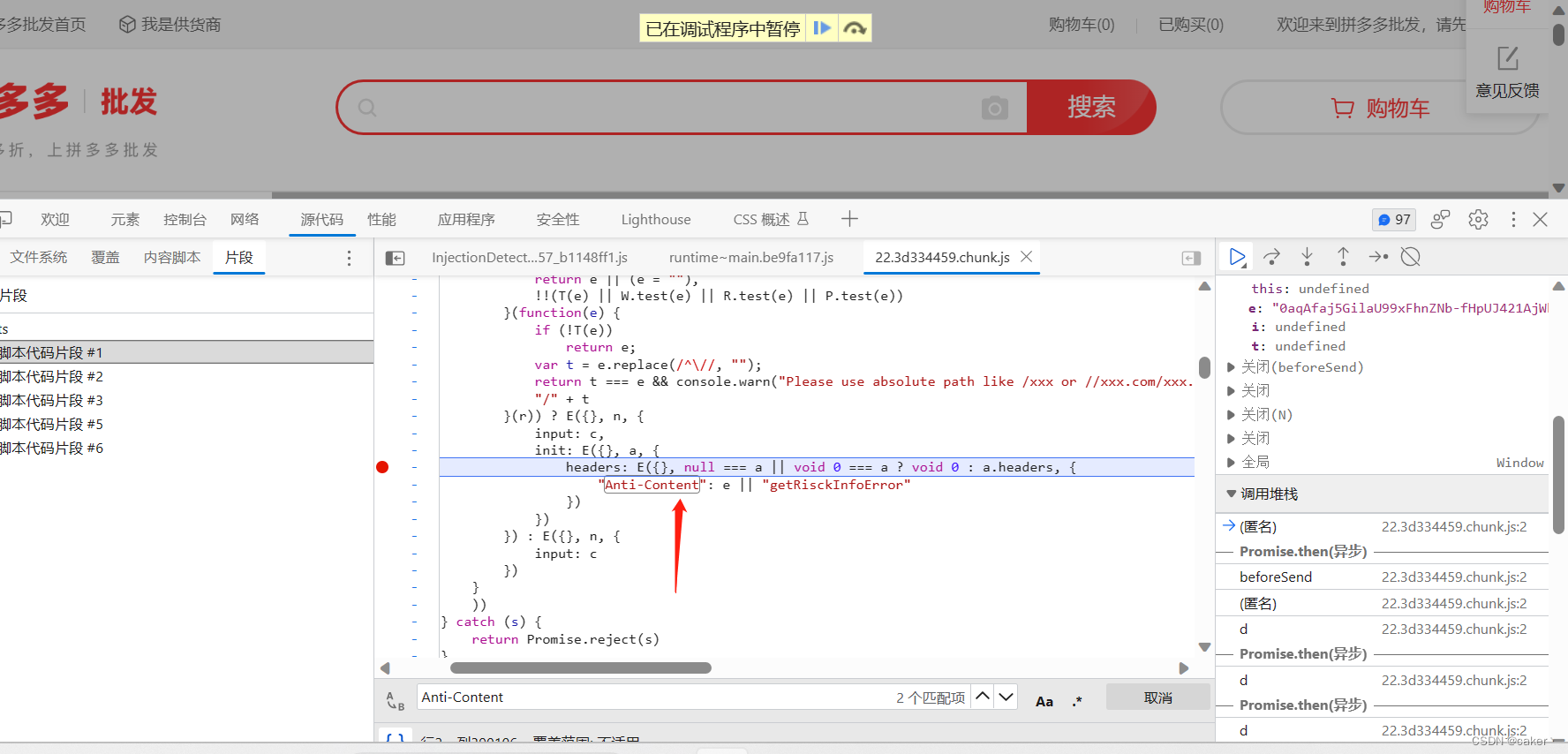
某多多商品平台数据采集
某多多商品平台数据采集 声明逆向目标寻找加密位置代码分析补环境补充内容声明
本文章中所有内容仅供学习交流,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者 无关,若有侵权,请私信我立即删除!
逆向目标
Anti-Content参数 寻找加密位置
先在控制台全局搜…
什么是 JSON:理解和运用 JSON 的基本概念
现在程序员还有谁不知道 JSON 吗?无论对于前端还是后端,JSON 都是一种常见的数据格式。那么 JSON 到底是什么呢?
JSON 的定义
JSON (JavaScript Object Notation) ,是一种轻量级的数据交换格式。它的使用…
100天精通Python(实用脚本篇)——第116天:基于selenium实现反反爬策略之添加cookie登录网站
文章目录 专栏导读1. cookie是什么?2. cookie登录网站的优点?3. 浏览器怎么查看cookie?4. 代码获取cookie5. 添加cookie登录网站专栏导读
🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的…
网络爬虫实践1-爬取百度文库,存入Word文档
本文主要参考文章<使用Selenium爬取百度文库word文章>,在这里要感谢作者的分享。 本文主要就是代码,因为代码里有详细的注释说明。所以,就不再文字描述了。各位看官们,直接看代码和注释吧。
# -*- coding: utf-8 -*-from s…
使用python实现第一个网络爬虫
什么是网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、…
如何获取抖音订单API数据接口?
在开放平台中,每个API接口都有相应的文档说明和授权机制,以确保数据的安全性和可靠性。开发者可以根据自己的需求选择相应的API接口,并根据文档说明进行调用和使用。
开放平台API接口是一套REST方式的开放应用程序编程接口,它…
【小沐学Python】网络爬虫之lxml
文章目录 1、简介2、安装3、基本功能3.1 lxml.etree3.2 解析HTML网页3.3 读取并解析HTML文件3.4 提取所有a标签内的文本信息3.5 树迭代3.6 序列化3.7 元素以字典的形式携带属性3.8 元素包含文本 4、代码测试4.1 lxml解析网页4.2 使用xpath获取所有的文本4.3 使用xpath获取 clas…
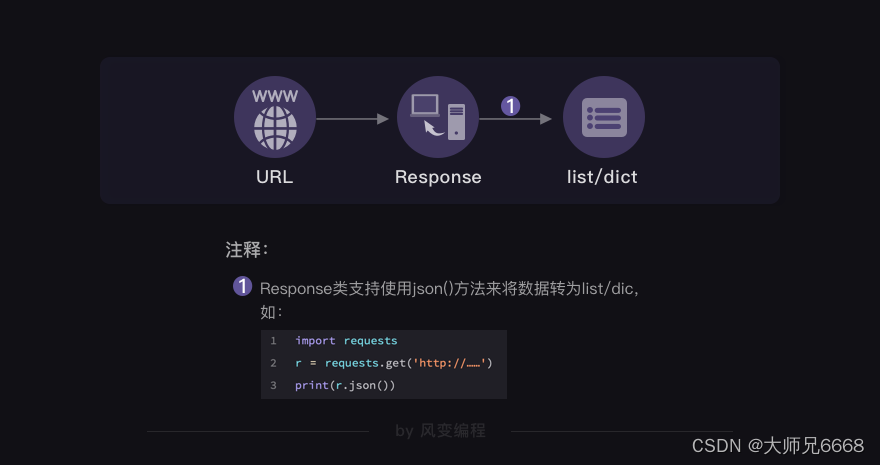
Python爬虫之Ajax数据爬取基本原理
前言
有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用 requests 得到的结果并没有。这是因为 requests 获取的都是原始的 HTML 文档,而浏览器中…

开发的功能不都是经过上线测试,为什么上线后还会那么多 Bug ?
你是否也经过这样的灵魂拷问:「开发的功能不都是经过上线测试的吗?为什么上线后还会那么多 Bug ?」。 大家明明都很努力,为什么「输出」的结果没有更进一步?今天我们就水一水这个「狗血」话题,究竟是谁个锅…
淘宝商品API使用示例:如何通过调用外部API来获取淘宝商品价格销量主图详情数据
淘宝上的商品信息量非常之大,商品的详情信息也很齐全。如何通过调用外部API来实现批量获取商品价格销量主图详情等信息呢?上周刚好完成了一个完整的淘宝商品采集项目,今天特来分享一下。
接口名称:item_get
请求地址:…

如何使用Puppeteer进行金融数据抓取和预测
导语
Puppeteer是一个基于Node.js的库,可以用来控制Chrome或Chromium浏览器,实现网页操作、截图、PDF生成等功能。本文将介绍如何使用Puppeteer进行金融数据抓取和预测,以及如何使用亿牛云爬虫代理提高爬虫效果。
概述
金融数据抓取是指从…
调用电商API你不得不知道的几件事
随着电商市场的迅速发展,越来越多的商家选择通过电商平台进行销售。为了达到更好的销售效果,许多商家开始尝试使用电商API。但是在使用电商API之前,商家需要了解一些必要的事情,以确保正常调用API并减少可能的风险。
本文将从以下…
最近在对接电商供应链,说说开放平台API接口
B2B电商开放平台的设计需要从以下几面去思考: 开放平台API接口的设计,主要是从功能需求的角度,设计满足业务需求的接口及对应的字段; 平台与商家之间信息的对接,对接的方法有哪些?对接过程中需要可能会遇到…
拼多多订单打单接口 免申请审核流程接入(拼多多开放平台接入)
pdd.erp.order.sync
erp打单信息同步
更新时间:2021-04-13 23:04:54
免费API必须用户授权
erp打单信息同步
公共参数
名称类型必须描述keyString是调用key(注册获取APIkey)secretString是调用密钥api_nameString是API接口名称ÿ…

通过Siri打造智能爬虫助手:捕获与解析结构化数据
在信息时代,我们经常需要从互联网上获取大量的结构化数据。然而,传统的网络爬虫往往需要编写复杂代码和规则来实现数据采集和解析。如今,在苹果公司提供的语音助手Siri中有一个强大功能可以帮助我们轻松完成这项任务——通过使用自定义指令、…

使用Puppeteer爬取地图上的用户评价和评论
导语
在互联网时代,获取用户的反馈和意见是非常重要的,它可以帮助我们了解用户的需求和喜好,提高我们的产品和服务质量。有时候,我们需要从地图上爬取用户对某些地点或商家的评价和评论,这样我们就可以分析用户对不同…
Nutch的URL选择策略 OPIC IN NUTCH
突 然发现这句话对于网络爬虫也是很有启发意义的,对于浩瀚无边的互联网而言,网络爬虫涉及到页面确实只是冰山一角。因此,如何确定一个页面的重要性,从而在 抓取过程中进行合理的调度,以最小的代价(硬件、带…

Google搜索产品经理:搜索仍有很大的创新和发展空间
【编者按】本文作者Drew Olanoff是TechCrunch的网站编辑,有着丰富的工作经验,市场营销、客户服务、客户关系管理、产品管理、技术支持等等方面都有涉足,他称自己为“连线者”,工作是将人、故事和信息连接起来。 上周我参观了Googl…
2023爬虫学习笔记 -- 某狗网站爬取数据
一、爬取某狗网站的首页1、导入需要的库文件import requests2、指定我们要访问的网址网页"https://www.sogou.com"3、获取服务器的返回的所有信息响应requests.get(网页)4、通过text属性,从返回信息中读取字符串内容响应内容响应.text5、查看读取到的内容…

爬虫进阶之多线程爬虫问题详解
大多数正常人在下载图片的时候都是一个一个点击保存,图片越多花费的时间越多,大大的降低了工作效率。如果是学了爬虫的,一定会想到多线程来自动下载保存图片。
多线程介绍:
多线程是为了同步完成多项任务,通过提高资…
【Python_Scrapy学习笔记(一)】Scrapy框架简介
Scrapy框架简介
前言
Scrapy 框架是一个用 python 实现的为了爬取网站数据、提取数据的应用框架,使用 Twisted 异步网络库来处理网络通讯,可以高效的完成数据爬取。本文主要介绍 Scrapy 框架的构成与工作原理。
正文
1、Scrapy安装
Windows安装&…

Disabled PicPipeline: ImagesPipeline requires installing Pillow 4.0.0 or later
目录
一、scrapy是什么
二、问题以及原因
三、解决办法
1、确保系统已经安装了 Pillow 库。
2、安装 Pillow 库。
3、在项目根目录中添加 Pillow 的 .pth 文件。 一、scrapy是什么 Scrapy是一个用于从网站和Web应用中抓取数据的强大的Python库。Scrapy支持异步I/O和
Scr…

明明加了唯一索引,为什么还是产生了重复数据?
前言
前段时间我踩过一个坑:在mysql8的一张innodb引擎的表中,加了唯一索引,但最后发现数据竟然还是重复了。
到底怎么回事呢?
本文通过一次踩坑经历,聊聊唯一索引,一些有意思的知识点。 1.还原问题现场 …

【数据分析与挖掘】数据分析学习及跟课学习 | csdn_Part 03 编程部分 上篇
这部分跟的课是前段时间没有电脑使用平板及纸笔记得,所以主要的目的是为了将纸质笔记转为电子版,加上适当的练习,配合回顾,争取把数据分析知识基础过一遍,能够掌握最好。
第五章 正则表达式的使用
正则表达式是指专门…
海量数据处理系列——BloomFilter
引自http://www.cnblogs.com/heaad/archive/2011/01/02/1924195.html
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。 一. 实例 为了说明Bloom Filter…

爬虫程序中使用爬虫ip的优势
作为一名爬虫技术员,我发现在爬虫程序中使用代理IP可以提升爬取效率和匿名性。今天,我就来详细讲解一下代理IP在爬虫程序中的工作原理及应用。
首先,我们来了解一下代理IP在爬虫程序中的工作原理。当我们使用爬虫程序进行数据采集时…
每天一个电商API分享:获取拼多多订单数据接口
拼多多是国内知名的社交电商平台,为商家提供了订单接口以便更好地管理和处理订单。本文将详细介绍拼多多官方订单接口的接入指南,帮助商家快速接入并正确使用订单接口。 接入准备 在接入拼多多官方订单接口之前,商家需要完成以下准备工作&…

带你彻底了解什么是API接口?
作为一名资深程序员,我知道很多人对API接口这个名词可能还不太了解。今天我要给大家分享一些关于API接口的知识,让你们彻底了解它的概念和作用。一起来看看吧! 首先,我们先来解释一下API的全称─Application Programming Interfac…

阿里巴巴国际站商品详情接口,商品列表接口(免费测试)
随着全球经济的发展和互联网技术的进步,跨境电商已经成为了许多企业拓展市场、实现增长的重要方式。阿里巴巴国际站作为全球知名的跨境电商平台,为各类企业和消费者提供了便捷高效的贸易服务。其中,商品详情接口和商品列表接口是阿里巴巴国际…
拼多多app商品详情接口 获取pdd商品主图价格销量库存信息
拼多多是中国一家知名的电商平台,以"社交团购新零售"的商业模式闻名,通过手机app和微信小程序等渠道提供商品销售和购物体验。平台上的商品种类丰富多样,涵盖了服装、家居、美妆、食品、数码电子等各个领域。
拼多多的商业模式主要…
淘宝app商品详情原数据接口API(支持高并发请求/免费测试)
item_get_app-获得淘宝app商品详情原数据
一、引言
随着移动互联网的迅速发展,移动电商应用的需求也在不断增长。淘宝作为中国最大的电商平台之一,每天需要处理大量的商品数据和用户访问请求。为了提供更加优质的用户体验,淘宝开放了商品详…
Python爬虫之非关系型数据库存储#5
NoSQL,全称 Not Only SQL,意为不仅仅是 SQL,泛指非关系型数据库。NoSQL 是基于键值对的,而且不需要经过 SQL 层的解析,数据之间没有耦合性,性能非常高。
非关系型数据库又可细分如下。
键值存储数据库&am…
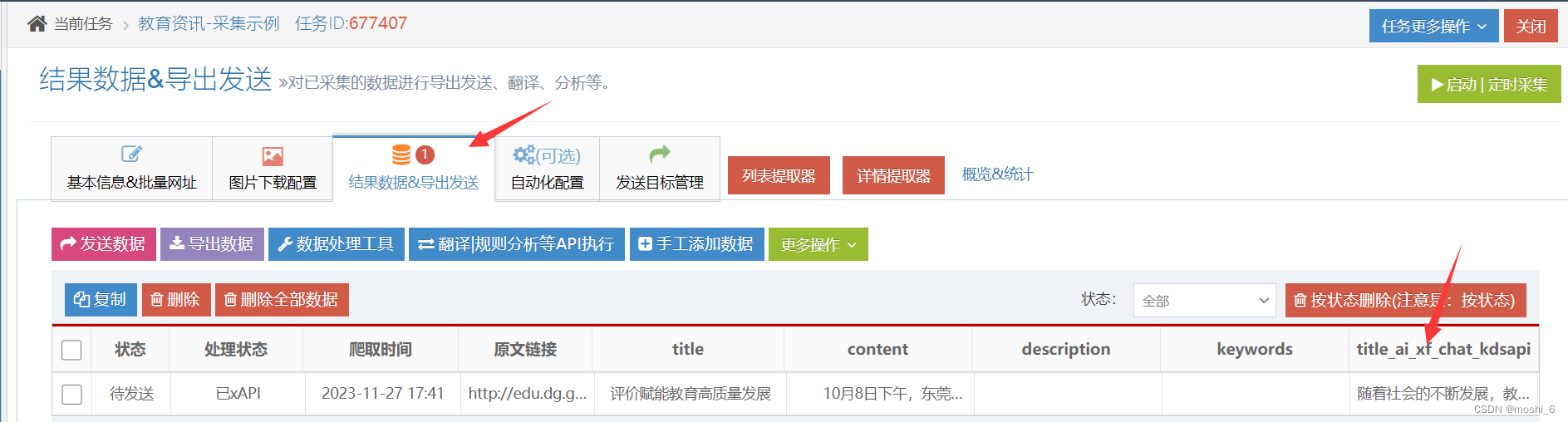
如何使用科大讯飞星火大模型AI批量生成文章
如何使用科大讯飞的星火大模型AI工具批量生成文章呢?
我们可以使用科大讯飞AI的星火大模型API接口,它支持批量处理和生成文章的AI功能。
但是星火大模型API接口无法直接使用,一般需要技术人员开发对应程序对接才行。为了让不懂技术的普通用…
一个程序员眼中的API调用(淘宝/天猫/1688/拼多多API)
在程序员眼中,API调用是一种重要的编程概念,它允许开发人员通过预先定义好的接口和规范,调用其他应用程序或服务的功能。API调用是现代软件开发中不可或缺的一部分,它使得开发人员能够快速构建出复杂的应用程序,同时避…
电商API:淘宝京东拼多多1688多电商平台的商品销量库存信息获取
item_get 获得淘宝商品详情 获取APIkeyitem_get_pro 获得淘宝商品详情高级版item_review 获得淘宝商品评论item_fee 获得淘宝商品快递费用item_password 获得淘口令真实urlitem_list_updown 批量获得淘宝商品上下架时间seller_info 获得淘宝店铺详情item_search 按关键字搜索淘…

Scala爬虫实战:采集网易云音乐热门歌单数据
导言
网易云音乐是一个备受欢迎的音乐平台,汇集了丰富的音乐资源和热门歌单。这些歌单涵盖了各种音乐风格和主题,为音乐爱好者提供了一个探索和分享音乐的平台。然而,有时我们可能需要从网易云音乐上获取歌单数据,以进行音乐推荐…
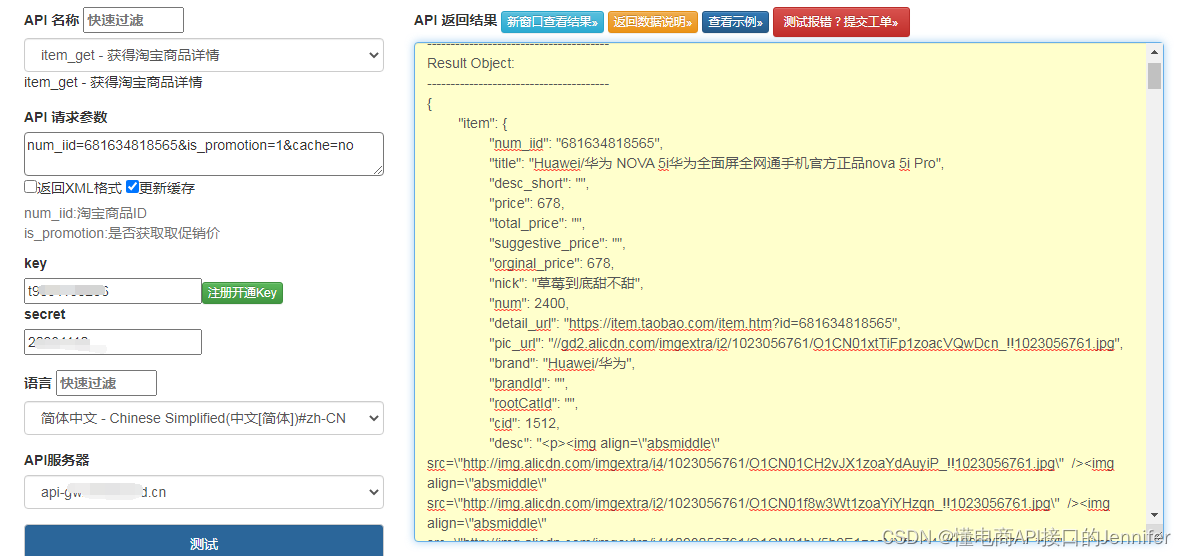
【Python爬虫】网页抓取实例之淘宝商品信息抓取
之前我们已经说过网页抓取的相关内容
上次我们是以亚马逊某网页的产品为例
抓取价格、品牌、型号、样式等 该网页上价格、品牌、型号、样式等
都只有一个
如果网页上的目标内容
根据不同规格有多个
又该怎么提取呢?
▼如下图所示 当机身颜色、套餐、存储容量…

实用技巧:在C和cURL中设置代理服务器爬取www.ifeng.com视频
概述:
网络爬虫技术作为一种自动获取互联网数据的方法,在搜索引擎、数据分析、网站监测等领域发挥着重要作用。然而,面对反爬虫机制、网络阻塞、IP封禁等挑战,设置代理服务器成为解决方案之一。代理服务器能够隐藏爬虫的真实IP地…
免费的网页采集器工具推荐有哪些
免费好用的全自动网页采集器工具有哪些?
本文精心挑选出三款主流优秀的数据采集器软件,列举出它们的差异和各自的优缺点,希望能帮助您找到最符合您需求的采集工具!
目录
1. 火车头采集器工具
火车头采集器软件优点
不足之处 …

spider 网页爬虫中的 AWS 实例数据获取问题及解决方案
前言
AAWS实例数据对于自动化任务、监控、日志记录和资源管理非常重要。开发人员和运维人员可以通过AWS提供的API和控制台访问和管理这些数据,以便更好地管理和维护他们在AWS云上运行的实例。然而,在使用 spider 框架进行网页爬取时,我们常常…
PHP调用API接口的方法及实现
随着互联网、云计算和大数据时代的到来,越来越多的应用程序需要调用第三方的API接口来获取数据,实现数据互通和协同工作。PHP作为一种常用的服务器端语言,也可以通过调用API接口来实现不同系统的数据交互和整合。本文将介绍PHP调用API接口的方…
大数据机器学习算法项目——基于Django/协同过滤算法的房源可视化分析推荐系统的设计与实现
大数据机器学习算法项目——基于Django/协同过滤算法的房源可视化分析推荐系统的设计与实现
技术栈:大数据爬虫/机器学习学习算法/数据分析与挖掘/大数据可视化/Django框架/Mysql数据库
本项目基于 Django框架开发的房屋可视化分析推荐系统。这个系统结合了大数据…
整站下载保存为mhtml
整站下载保存为mhtml 代码MHTML格式具有独特的优点,它可以完整保留原始网页的所有布局元素以及嵌入图片,无需外部依赖即可呈现原始网页内容,增强了可读性和便捷性。下文将展示如何运用自动化技术,从一个网站的首页出发,采用递归爬取的方式遍历整个站点,并将抓取到的各个页…
淘宝app商品详情API 获取淘宝app商品销量价格主图详情API (可获取测试key)
item_get_app-获得淘宝app商品详情原数据
公共参数
点此获取调用key&secret
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_…
Playwright报错TypeError: Plain typing.NoReturn is not valid as type argument
我试了无数个方法去解决报错结果全都是徒劳!!!!! 最终发现是python版本过低导致的,我的python版本是3.7.0,而需要3.7.0以上的版本,比如3.7.2、3.7.5或者3.8的版本都可以 真是服了啊&…

安卓逆向 - EdXposed LSPosed VirtualXposed
一、引言
接上篇:安卓逆向 - Xposed入门教程_小馒头yy的博客-CSDN博客 我们介绍了Xposed入门安装使用,但是只支持到Android 8,并且安装模块需要重启。今天我们来看看Xposed的其他版本。
二、各种Xposed框架对比
1、Xposed 只支持到安卓8&…

淘宝商品sku信息抓取接口api
在电商行业中,SKU是一个经常被使用的术语,但是对于很多人来说,这个词可能还比较陌生。在这篇文章中,我们将详细解释什么是SKU,以及在电商业务中它的作用和意义。
什么是SKU?
SKU是“Stock Keeping Unit”…

探索自动化测试工具:Selenium的威力与应用
文章目录 🍋引言🍋什么是Selenium?🍋Selenium的特点🍋如何使用Selenium进行自动化测试?🍋行为链 🍋用例示例:Web应用程序自动化测试🍋Selenium的一些常用语法…

如何爬取动态加载的图片数据
百度图片是一个非常受欢迎的图片分享平台,其中包含了大量的图片资源。然而,百度图片使用了动态加载技术,使得Python爬虫在获取百度动态加载图片时面临一定的难度。百度图片使用了动态加载技术,这意味着图片并不是一次性全部加载出…

电商狂欢双11,该使用什么API?
taobao API 接入说明
API接入地址 参数说明 通用参数说明 参数不要乱传,否则不管成功失败都会扣费url说明 https://api-seaver.cn/平台/API类型/ 平台:淘宝,京东等, API类型:[item_search,item_get,item_search_shop等]version:A…

Python大数据实践:selenium爬取京东评论数据
准备工作
selenium安装
Selenium是广泛使用的模拟浏览器运行的库,用于Web应用程序测试。 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,并且支持大多数现代 Web 浏览器。
#终端pip安装
pip install selenium
#清华镜像安装
p…
【爬虫】web自动化和接口自动化
专栏文章索引:爬虫 目录
一、介绍
二、推荐
1.接口自动化
2.Web自动化 一、介绍
爬虫技术一般可以分为两种类型:接口自动化和web自动化。下面是它们的简要介绍:
1.接口自动化
接口自动化技术的主要目的是通过模拟HTTP请求来实现自动化…

python代理服务器搭建,Python代理IP怎么使用?
随着互联网的普及,越来越多的人开始关注网络安全和隐私保护。代理服务器是一种可以隐藏用户真实IP地址的工具,通过代理服务器可以让人们在使用网络时更加安全和隐蔽。搭建Python代理服务器可以让我们更好地了解网络协议、加强网络安全等。 搭建Python代理…
亚马逊哪个站点好做?亚马逊全球站点介绍!
前言
亚马逊全球有18个站点,其中七大站点分别为:北美站、欧洲站、日本站、澳洲站、印度站、中东站、新加坡站。按照国家和地区分为中国、美国、加拿大、墨西哥、英国、德国、法国、西班牙、意大利、澳大利亚、日本、印度、土耳其、中东和巴西。不同的站…
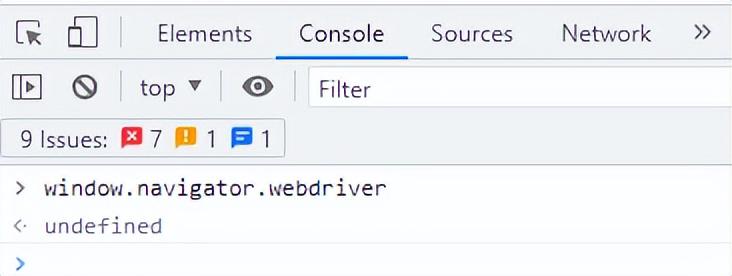
2023爬虫学习笔记 -- selenium反爬虫操作(window.navigator.webdriver属性值)
一、无可视化浏览器操作1、导入需要的函数,固定写法,并设置相关浏览器参数from selenium.webdriver.chrome.options import Options浏览器设置Options()
浏览器设置.add_argument("--headless")
浏览器设置.add_argument("--disable-gpu&…

使用Objective-C和ASIHTTPRequest库进行Douban电影分析
概述
Douban是一个提供图书、音乐、电影等文化内容的社交网站,它的电影频道包含了大量的电影信息和用户评价。本文将介绍如何使用Objective-C语言和ASIHTTPRequest库进行Douban电影分析,包括如何获取电影数据、如何解析JSON格式的数据、如何使用代理IP技…

C#和HttpClient结合示例:微博热点数据分析
概述
微博是中国最大的社交媒体平台之一,它每天都会发布各种各样的热点话题,反映了网民的关注点和舆论趋势。本文将介绍如何使用C#语言和HttpClient类来实现一个简单的爬虫程序,从微博网站上抓取热点话题的数据,并进行一些基本的…

【Python_Scrapy学习笔记(十二)】基于Scrapy框架实现POST请求爬虫
基于Scrapy框架实现POST请求爬虫
前言
本文中介绍 如何基于 Scrapy 框架实现 POST 请求爬虫,并以抓取指定城市的 KFC 门店信息为例进行展示
正文
1、Scrapy框架处理POST请求方法
Scrapy框架 提供了 FormRequest() 方法来发送 POST 请求; FormReques…
某音a_bogus 流程vmp分析
声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
目标网站
仅研究。网站链接自己去找。
前言
这里a_bogus 又是个vmp。 还是个多层嵌套…
【爬虫框架Scrapy】02 Scrapy入门案例
接下来介绍一个简单的项目,完成一遍 Scrapy 抓取流程。通过这个过程,我们可以对 Scrapy 的基本用法和原理有大体了解。
1. 本节目标
本节要完成的任务如下。 创建一个 Scrapy 项目。 创建一个 Spider 来抓取站点和处理数据。 通过命令行将抓取的内容…

Scala中如何使用Jsoup库处理HTML文档?
在当今互联网时代,数据是互联网应用程序的核心。对于开发者来说,获取并处理数据是日常工作中的重要一环。本文将介绍如何利用Scala中强大的Jsoup库进行网络请求和HTML解析,从而实现爬取京东网站的数据,让我们一起来探索吧…

跨越网络边界:借助C++编写的下载器程序,轻松获取Amazon商品信息
背景介绍
在数字化时代,数据是新的石油。企业和开发者都在寻找高效的方法来收集和分析网络上的信息。亚马逊,作为全球最大的电子商务平台之一,拥有丰富的商品信息,这对于市场分析和竞争情报来说是一个宝贵的资源。
问题陈述
然…
爬虫案例-使用Session登录某知名网站(JS逆向AES-CBC加密+MD5加密)
总体概览:使用Session登录该网站,其中包括对password参数进行js逆向破解 (涉及加密:md5加密AES-CBC加密)
难度:两颗星
目标网址:aHR0cHM6Ly93d3cuZnhiYW9nYW8uY29tLw
下面文章将分为四个部分…
深入理解Python线程池ThreadPoolExecutor
Python线程池ThreadPoolExecutor 1、concurrent.futures2、submit()3、map()4、案例:多线程爬虫声明: 本文主要参考文章:https://www.jianshu.com/p/b9b3d66aa0be 尊重原创,如有侵权,请联系删除 1、concurrent.futures 从Python3.2开始,标准库为我们提供了concurrent.fut…
【Python全栈_公开课学习记录】
一、初识python (一).Python起源
Python创始人为吉多范罗苏姆(荷兰),Python崇尚优美、清晰、简明的编辑风格。Python语言结构清晰简单、数据库丰富、运行成熟稳定,科学计算统计分析领先。目前广泛应用于云计算、Web开发、科学运算…
国家统计局教育部各级各类学历教育学生情况数据爬取
教育部数据爬取 1、数据来源2、爬取目标3、网页分析4、爬取与解析5、如何使用Excel打开CSV1、数据来源 国家统计局:http://www.stats.gov.cn/sj/ 教育部:http://www.moe.gov.cn/jyb_sjzl/ 数据来源:国家统计局教育部文献教育统计数据2021年全国基本情况(各级各类学历教育学…
爬虫试用 | 京东商品详情搜索采集助手 – 一键批量采集下载商品详情
商品详情页(链接中可获取商品ID) API接口调用代码
Request address: https://api-服务器.cn/jd/item_get/?key【你的key】& &num_iid10335871600&cacheno&&langzh-CN&secret【你的密钥】
点此获取APIkey和secret
响应示例…
【学习心得】Python调用JS的三种常用方法
在做JS逆向的时候,一种情况是直接用Python代码复现JS代码的功能,达成目的。但很多时候这种方法有明显的缺点,那就是一旦JS代码逻辑发生了更改,你就得重写Python的代码逻辑非常不便。于是第二种情况就出现了,我直接得到…
收盘价时空模式挖掘与多股票走势聚类分析:探索市场行为共性
收盘价时空模式挖掘与多股走势聚类分析:探索市场行为共性 一.版本信息二.操作步骤1.下载各股历史交易数据A.代码(download_stocks.py)B.执行2.遍历各股的csv文件,提取收盘价数据,归一化,绘制曲线,保存图片A.代码B.执行3.用上面的图片集训练VAE模型A.代码B.执行4.用上面训出的V…
【2024】利用python爬取csdn的博客用于迁移到hexo,hugo,wordpress...
前言
博主根据前两篇博客进行改进和升级
利用python爬取本站的所有博客链接-CSDN博客文章浏览阅读955次,点赞6次,收藏19次。定义一个json配置文件方便管理现在文件只有用户名称,后续可加配置读取用户名称,并且将其拼接成csdn个人博客链接ty…

python爬虫之app爬取-mitmproxy 的使用
mitmproxy 的使用
mitmproxy 是一个支持 HTTP 和 HTTPS 的抓包程序,有类似 Fiddler、Charles 的功能,只不过它是一个控制台的形式操作。
mitmproxy 还有两个关联组件。一个是 mitmdump,它是 mitmproxy 的命令行接口,利用它我们可以对接 Python 脚本,用 Python 实现监听后…

【学习心得】爬虫JS逆向通解思路
我希望能总结一个涵盖大部分爬虫逆向问题的固定思路,在这个思路框架下可以很高效的进行逆向爬虫开发。目前我仍在总结中,下面的通解思路尚不完善,还望各位读者见谅。
一、第一步:明确反爬手段
反爬手段可以分为几个大类
&#…
爬取博客的图片并且将它存储到响应的目录
目录 前言
思想
注意
不多说解释了,贴代码吧
config.json
Get_blog_img.py
把之前的写的代码也贴上
Get_blog_id.py
主函数
main.py
运行结果 前言
在上一篇博客中我们介绍了如何爬取博客链接
利用python爬取本站的所有博客链接-CSDN博客文章浏览阅读74…
基于Python的新浪微博爬虫程序设计与实现
完整下载:基于Python的新浪微博爬虫程序设计与实现.docx 基于Python的新浪微博爬虫程序设计与实现 Design and Implementation of a Python-based Weibo Web Crawler Program 目录 目录 2 摘要 3 关键词 4 第一章 引言 4 1.1 研究背景 4 1.2 研究目的 5 1.3 研究意义…
【学习心得】响应数据加密的原理与逆向思路
一、什么是响应数据加密? 响应数据加密是常见的反爬手段的一种,它是指服务器返回的不是明文数据,而是加密后的数据。这种密文数据可以被JS解密进而渲染在浏览器中让人们看到。 它的原理和过程图如下: 二、响应数据加密的逆向思路 …
小红书获得小红书笔记详情 API
小红书笔记详情 API 调用说明文档
一、背景
小红书是一个生活方式分享社区,用户可以在平台上发布和获取各类生活方式的笔记内容。为了提供更高效、更便捷的服务,我们开放了小红书笔记详情 API,供开发者查询小红书笔记的详细信息。
二、应用…
2023年下半场跨境电商发展的六大趋势,如何把握?
过去一年,全球经贸格局发生重大变化,跨境电商行业在各种不确定因素的影响下蜕变前行。从发展趋势来看,2023年的网上的消费需求不会减少,推动着跨境电商的规模增长。从政策上看,2023年跨境电商环境整体在持续恢复发展中…
抖音怎么隐藏自己真实IP地址?使用代理IP可以防止IP地址b不被攻击吗?
随着互联网的普及和网络社交的盛行,越来越多的人开始关注个人隐私保护问题,其中IP地址的隐藏成为了关注的焦点之一。在抖音等网络社交平台上,很多人希望隐藏自己的真实IP地址,以保护个人隐私和安全。那么,如何隐藏自己…
python爬取B站CC字幕(隐藏式字幕)
文章目录 字幕srt文件介绍subtitle_urlCC字幕爬取命名实体识别NER字幕srt文件介绍
srt 的全称是SubRip Text,是一种非常流行的文本字幕,包含一行时间,一行字幕,制作规范非常简单。
B站除了博主配置的原生字幕之外,还提供了一种智能生成的字幕——CC字幕,CC是Closed Cap…
Python下载音乐
今天我就来分享一下我的方法:Python爬虫
在CS dn社区中我浏览了许多关于爬虫代码,可都有各自的缺陷,有的需要ID比较麻烦,这里我编写了一个程序,他只需要输入歌曲名字即可进行搜索爬取并下载
话不多说,下面的程序复制…
诈骗分子投递“大闸蟹礼品卡”,快递公司如何使用技术手段提前安全预警?
目录
快递公司能不能提前识别?
如何通过技术有效识别
为即将带来的双十一提供安全预警 金秋十月,正是品尝螃蟹的季节。中秋国庆长假也免不了走亲访友,大闸蟹更是成了热门礼品。10月7日,演员孙艺洲发布微博称,“收到…
亮数据代理IP轻松解决爬虫数据采集痛点
文章目录 一、爬虫数据采集痛点二、为什么使用代理IP可以解决?2.1 爬虫和代理IP的关系2.2 使用代理IP的好处 三、亮数据代理IP的优势3.1 IP种类丰富3.1.1 动态住宅代理IP3.1.2 静态住宅代理IP3.1.3 机房代理IP3.1.4 移动代理IP 3.2 高质量IP全球覆盖3.3 超级代理服务…

Spark魔力:招聘网站数据深度分析系统
Spark魔力:招聘网站数据深度分析系统 简介数据集技术栈功能特点创新点 简介
在本文中,我们将介绍一款基于Spark的招聘网站数据分析系统,该系统使用爬取的前程无忧招聘数据。通过结合Flask、Pandas、PySpark、以及MySQL等技术,实现…
dy消息监控,python协议
2024年3月27日
dy消息监控,协议版本,有wss和轮训2种方式,支持监听好友和群消息,支持消息回复,消息类型包括如下:
表情,文本,作品,语音,图片,视频…

基于Python的电商特产数据可视化分析与推荐系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 利用网络爬虫技术从某东采集某城市的特产价格、销量、评论等数据,经过数据清洗后存入数据库,并实现特产销售、市场占有率、价格区间等多维度的可视化统计分析,并…

Python从入门到网络爬虫(函数详解)
前言
函数是变成语言中最常见的语法,函数的本质就是功能的封装。使用函数可以大大提高编程效率与程序的可读性。函数是能够实现特定功能的计算机代码而已,他是一种特定的代码组结构。 函数的作用
1.提升代码的重复利用率,避免重复开发相同代…
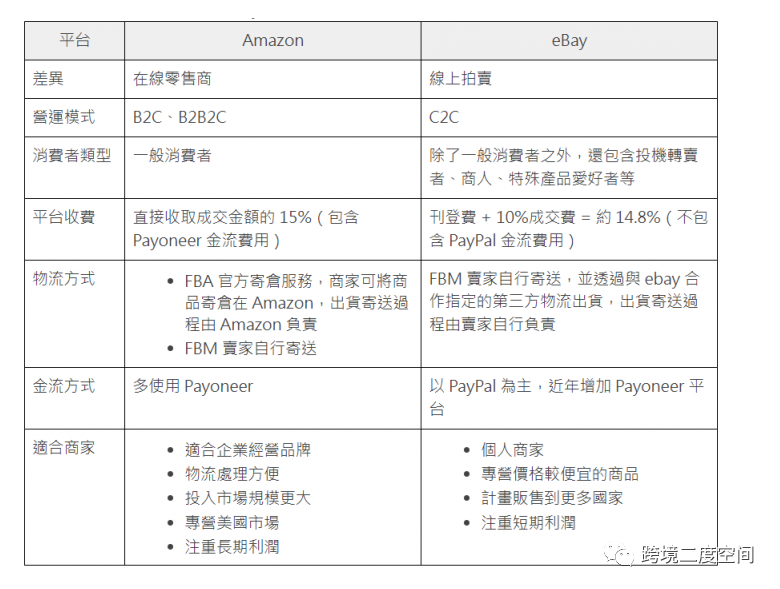
何谓跨境电商?跨境电商平台物流、金流、交易模式比较一篇搞懂
什么是跨境电商?
跨境电商的全名是跨境电子商务(Cross Border E-Commerce),从字面上分为两个元素:「跨境」与「电子商务」:
跨境:指的是跨越国家与国家之间的边境
电子商务:指的是…
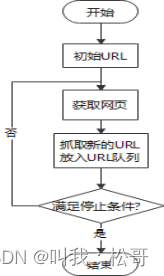
基于网络爬虫的天气数据分析
二、网络爬虫设计
网络爬虫原理 网络爬虫是一种自动化程序,用于从互联网上获取数据。其工作原理可以分为以下几个步骤:
定义起始点:网络爬虫首先需要定义一个或多个起始点(URL),从这些起始点开始抓取数据…

基于python flask茶叶网站数据大屏设计与实现,可以做期末课程设计或者毕业设计
基于Python的茶叶网站数据大屏设计与实现是一个适合期末课程设计或毕业设计的项目。该项目旨在利用Python技术和数据可视化方法,设计和开发一个针对茶叶行业的数据大屏,用于展示和分析茶叶网站的相关数据。 项目背景 随着互联网的快速发展,越…
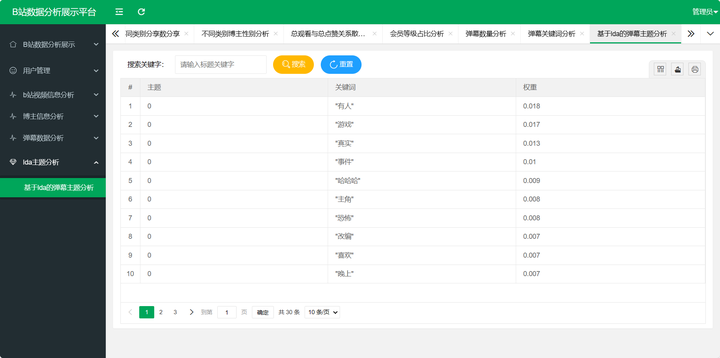
基于大数据的B站数据分析系统的设计与实现
摘要:随着B站(哔哩哔哩网)在国内视频分享平台的崛起,用户规模和数据量不断增加。为了更好地理解和利用这些海量的B站数据,设计并实现了一套基于Python的B站数据分析系统。该系统采用了layui作为前端框架、Flask作为后端…
Python爬虫http基本原理
HTTP 基本原理
在本节中,我们会详细了解 HTTP 的基本原理,了解在浏览器中敲入 URL 到获取网页内容之间发生了什么。了解了这些内容,有助于我们进一步了解爬虫的基本原理。
2.1.1 URI 和 URL
这里我们先了解一下 URI 和 URL,URI…
Python爬虫urllib详解
前言
学习爬虫,最初的操作便是模拟浏览器向服务器发出请求,那么我们需要从哪个地方做起呢?请求需要我们自己来构造吗?需要关心请求这个数据结构的实现吗?需要了解 HTTP、TCP、IP 层的网络传输通信吗?需要知…
Python爬虫Xpath库详解#4
爬虫专栏:http://t.csdnimg.cn/WfCSx
前言
前面,我们实现了一个最基本的爬虫,但提取页面信息时使用的是正则表达式,这还是比较烦琐,而且万一有地方写错了,可能导致匹配失败,所以使用正则表达式…
Python爬虫http基本原理#2
Python爬虫逆向系列(更新中):http://t.csdnimg.cn/5gvI3 HTTP 基本原理
在本节中,我们会详细了解 HTTP 的基本原理,了解在浏览器中敲入 URL 到获取网页内容之间发生了什么。了解了这些内容,有助于我们进一…
Python爬虫之Splash详解
爬虫专栏:http://t.csdnimg.cn/WfCSx
Splash 的使用
Splash 是一个 JavaScript 渲染服务,是一个带有 HTTP API 的轻量级浏览器,同时它对接了 Python 中的 Twisted 和 QT 库。利用它,我们同样可以实现动态渲染页面的抓取。
1. 功…
社交媒体欺诈乱象 | 每15人就有1人遭遇过网络欺诈!
目录
社交媒体的欺诈现象
欧盟要求科技公司加强虚假信息处理
借助技术识别虚假社交账号 据英国劳埃德银行(TSB)5月份发布的一份报告披露,社交媒体平台上的金融欺诈正在以令人担忧的速度增加,消费者应对Facebook、Instagram和Wh…

robots.txt 文件规则
robots.txt 是一种用于网站根目录的文本文件,其主要目的在于指示网络爬虫(web crawlers)和其他网页机器人(bots)哪些页面可以抓取,以及哪些页面不应该被抓取。可以看作是网站和搜索引擎机器人之间的一个协议…
Python爬虫-付费代理推荐和使用
付费代理的使用
相对免费代理来说,付费代理的稳定性更高。本节将介绍爬虫付费代理的相关使用过程。
1. 付费代理分类
付费代理分为两类: 一类提供接口获取海量代理,按天或者按量收费,如讯代理。 一类搭建了代理隧道࿰…
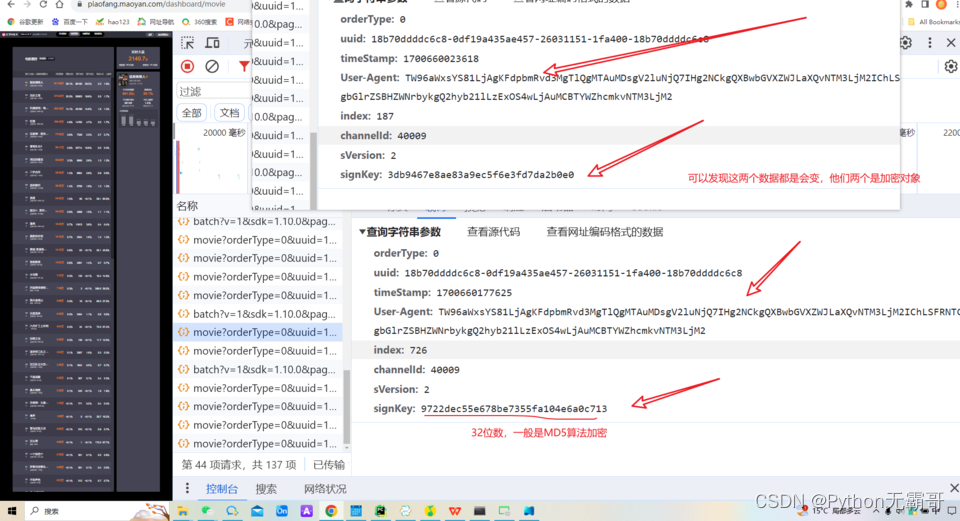
【爬虫逆向】Python逆向采集猫眼电影票房数据
进行数据抓包,因为这个网站有数据加密 !pip install jsonpathCollecting jsonpathDownloading jsonpath-0.82.2.tar.gz (10 kB)Preparing metadata (setup.py) ... done
Building wheels for collected packages: jsonpathBuilding wheel for jsonpath (setup.py) .…

⏰ 紧急通知【源码分享】:如何用Python自动获取并分享疫情风险数据
🌐 疫情监控自动化:中高风险地区数据采集与邮件通知系统
在这个全球抗击新冠疫情的关键时期,及时获取和分享中高风险地区的信息对于公共卫生安全至关重要。本文将深入探讨一个基于Python的自动化系统,该系统能够自动从网络获取最…
计算机毕业设计选题方向:Python与人工智能的结合
引言 在当今的计算机科学领域,Python语言因其简洁、易读和强大的库支持而备受青睐。特别是在人工智能(AI)领域,Python提供了丰富的工具和框架,使得开发智能应用变得更加高效。本指南旨在为计算机专业的学生提供一系列结…
Python实战一:获取某云app登录cookie
今天下午抽时间了解了python爬虫,简单认识了request库
需求:
因为天天需要登录某云app,帮别人签到,所以想写个python脚本来帮忙。
了解request库
request库是一个用于发送HTTP请求的库,可以用于向服务器发送GET、POST、PUT、D…
阿里巴巴按关键字搜索商品 API 返回值说明
item_search-按关键字搜索商品API测试工具
alibaba.item_search 公共参数
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,…
爬蟲IP代理詳細指南
收集數據算是比較麻煩的任務,尤其是當數據量很大時。在網路抓取時暴露IP地址是常有的事,所以需要用到代理抓取工具,提供高效可靠的數據提取。
爬蟲IP代理抓取工具到底指什麼,以及如何在各種情況下使用它,比如說繞過地…
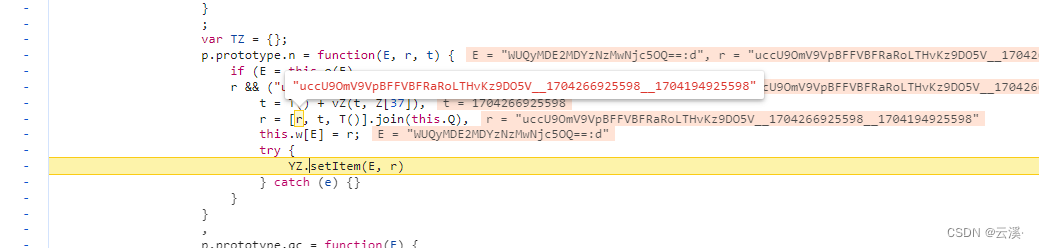
爬虫与反爬-localStorage指纹(某易某盾滑块指纹检测)(Hook案例)
概述:本文将用于了解爬虫中localStorage的检测原理以及讲述一个用于检测localStorage的反爬虫案例,最后对该参数进行Hook断点定位
目录:
一、LocalStorage
二、爬虫中localStorage的案例(以某盾滑块为例)
三、如何…
Python从入门到网络爬虫(内置函数详解)
前言
Python 内置了许多的函数和类型,比如print(),input()等,我们可以直接在程序中使用它们,非常方便,并且它们是Python解释器的底层实现的,所以效率是比一般的自定义函数更有效率。目前共有71个内置函数&…
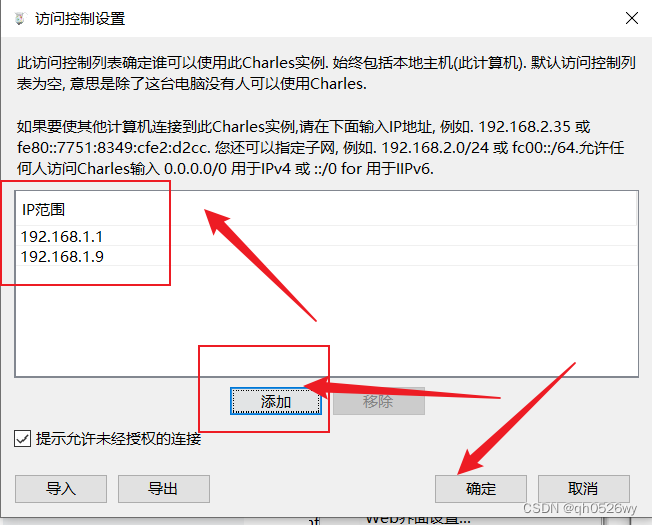
Charles抓包配置代理手机连接
Charles下载地址:
Charles_100519.zip官方版下载丨最新版下载丨绿色版下载丨APP下载-123云盘123云盘为您提供Charles_100519.zip最新版正式版官方版绿色版下载,Charles_100519.zip安卓版手机版apk免费下载安装到手机,支持电脑端一键快捷安装https://www.123pan.com…

Python零基础—网络爬虫入门,附学习路线+笔记+视频教程
这是本文的目录前言学习目标所需技能与Python版本所需技术能力选择Python的原因选择Python3.x的原因初识网络爬虫网络爬虫的概念1. 通用网络爬虫2. 聚焦网络爬虫3. 增量式网络爬虫4. 深层网络爬虫网络爬虫的应用Robots协议搜索引擎核心零基础Python学习资源介绍👉Py…
Python爬取电影信息:Ajax介绍、爬取案例实战 + MongoDB存储
Ajax介绍
Ajax(Asynchronous JavaScript and XML)是一种用于在Web应用程序中实现异步通信的技术。它允许在不刷新整个网页的情况下,通过在后台与服务器进行数据交换,实时更新网页的一部分。Ajax的主要特点包括: 异步通…
JsRpc技术服务搭建,最简单的JSRPC,Flask+undetected-chromedriver
只需10来行代码快速实现JSRpc,最简单的JSRPC
使用Flask和undetected-chromedriver快速实现JsRpc
推荐Python版本3.7.x及以上,需要pip安装
pip install Flask
pip install undetected-chromedriver
__author__ jiuLiang
__email__ "jiuliangef…
价值百万的企业大数据分析报告是如何炼成的?
很多企业往往会花高额价钱来请咨询公司对企业的整体经营情况做一个分析,生成一个报告。但是对于多数已经有数据管理的企业,可以针对一个具体企业、一个具体问题开展针对性的数据分析,从点到面地解决问题。现如今企业有了更多的数据来源途径和…
爬取东方财富股票信息
爬取股票信息
爬虫爬取信息,一般有两种大的思路,分别是:
模拟header信息,发送请求,得到相应的数据(html文件 或者 json数据)使用selenium模拟打开浏览器,然后利用selenium提供的函…

逆向爬虫进阶实战:突破反爬虫机制,实现数据抓取
文章目录 一、引言二、逆向爬虫进阶技巧三、逆向爬虫进阶实战代码片段四、总结与展望好书推荐内容简介作者简介前言节选 一、引言
随着网络技术的发展,网站为了保护自己的数据和资源,纷纷采用了各种反爬虫机制。然而,逆向爬虫技术的出现&…
Ajax介绍、爬取案例实战 + MongoDB存储
Ajax介绍
Ajax(Asynchronous JavaScript and XML)是一种用于在Web应用程序中实现异步通信的技术。它允许在不刷新整个网页的情况下,通过在后台与服务器进行数据交换,实时更新网页的一部分。Ajax的主要特点包括: 异步通…
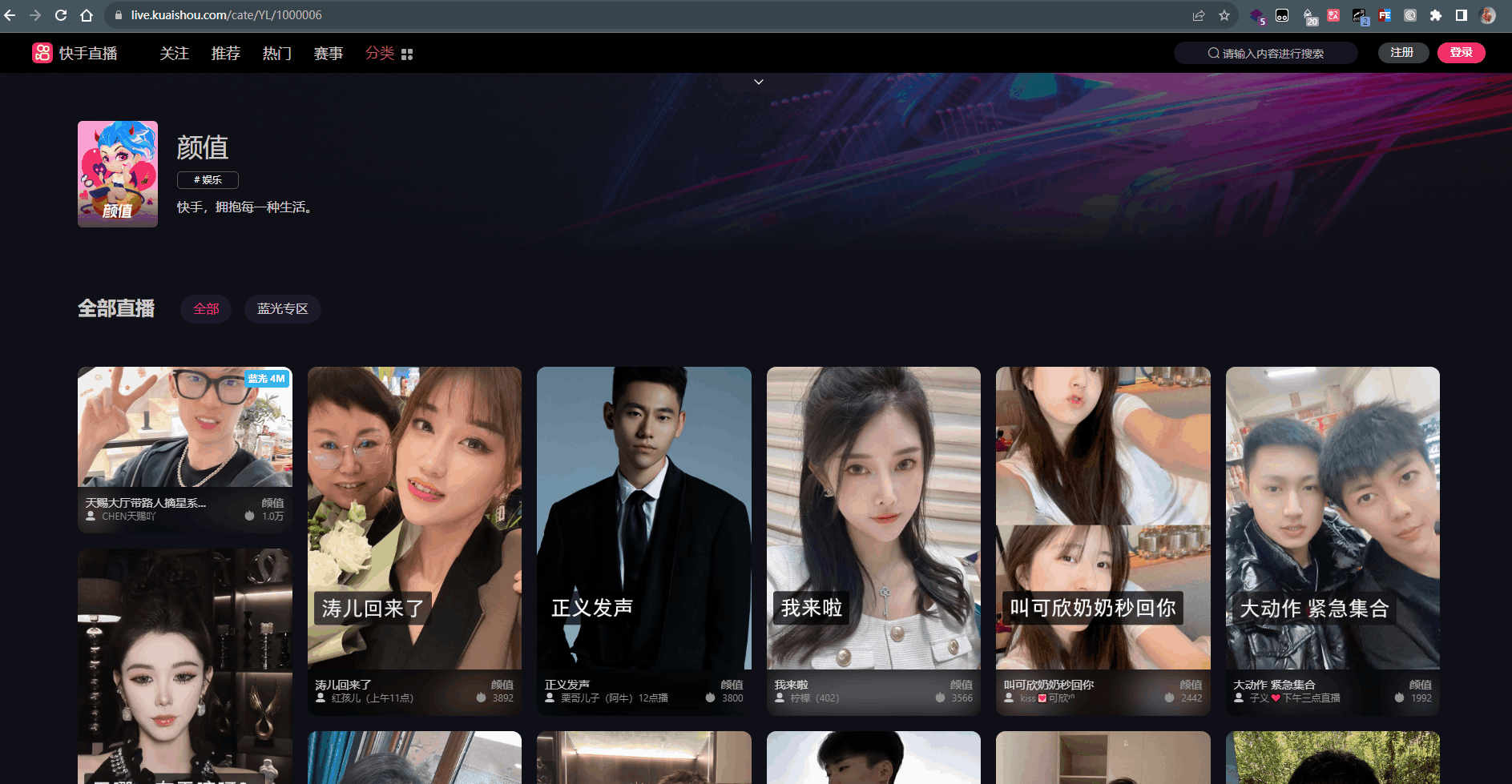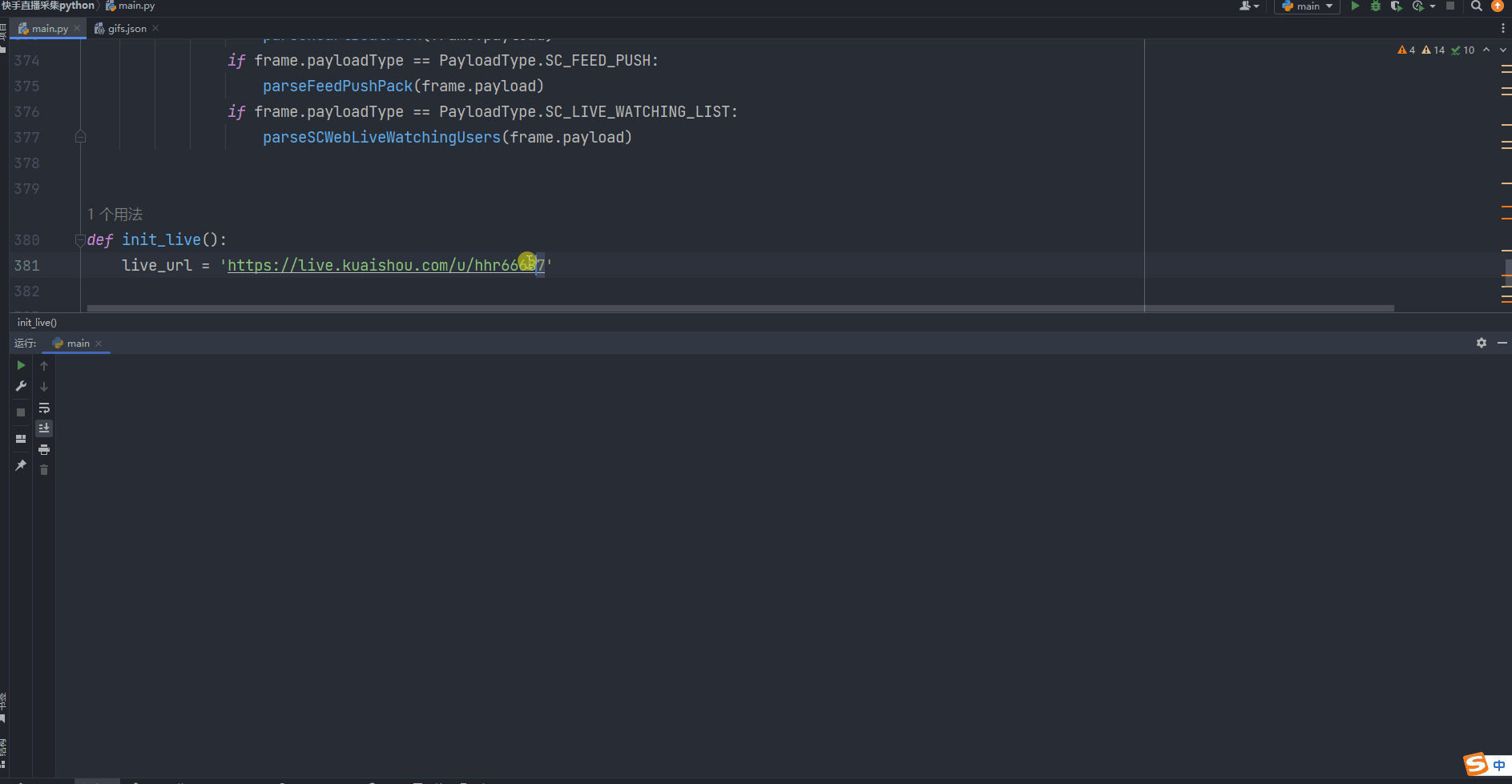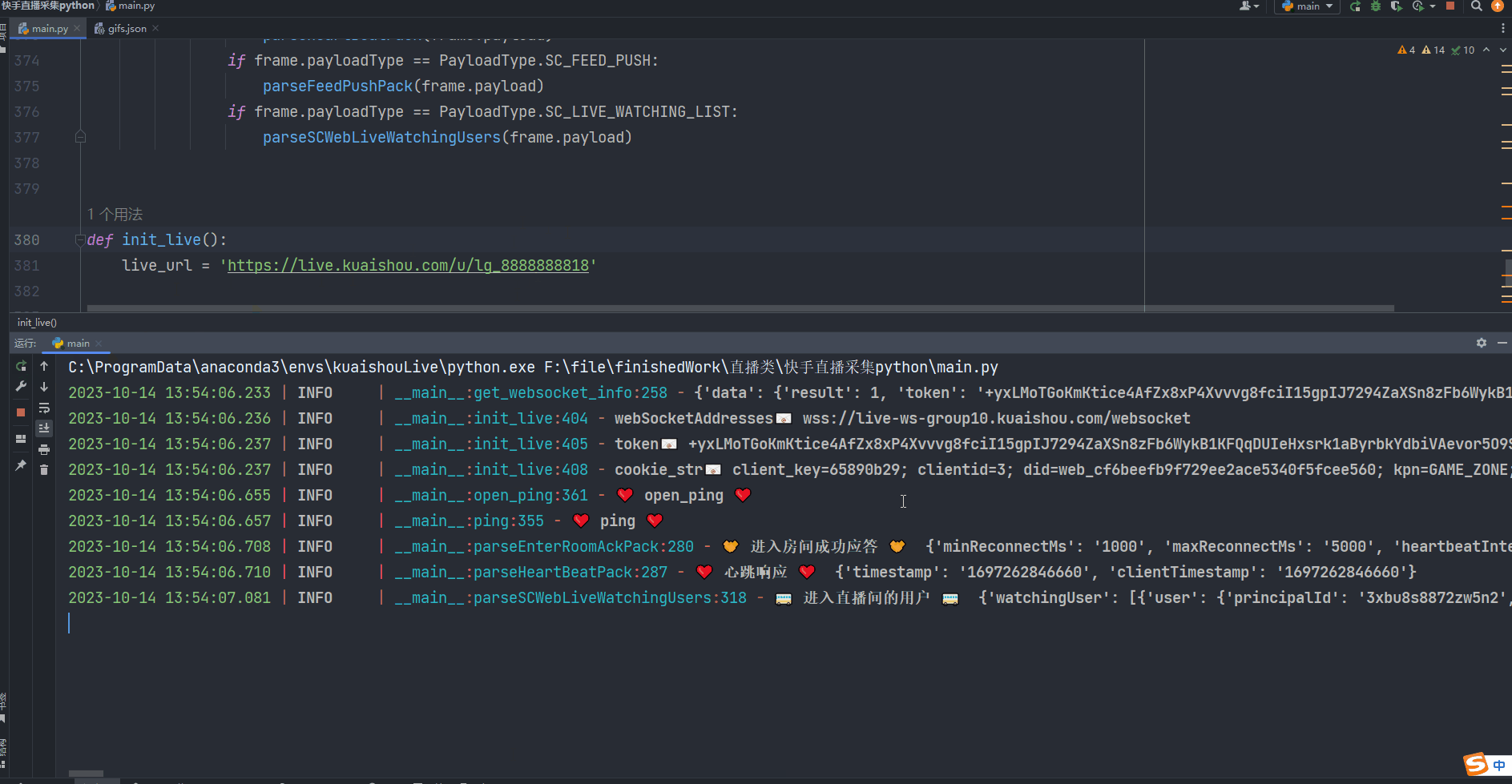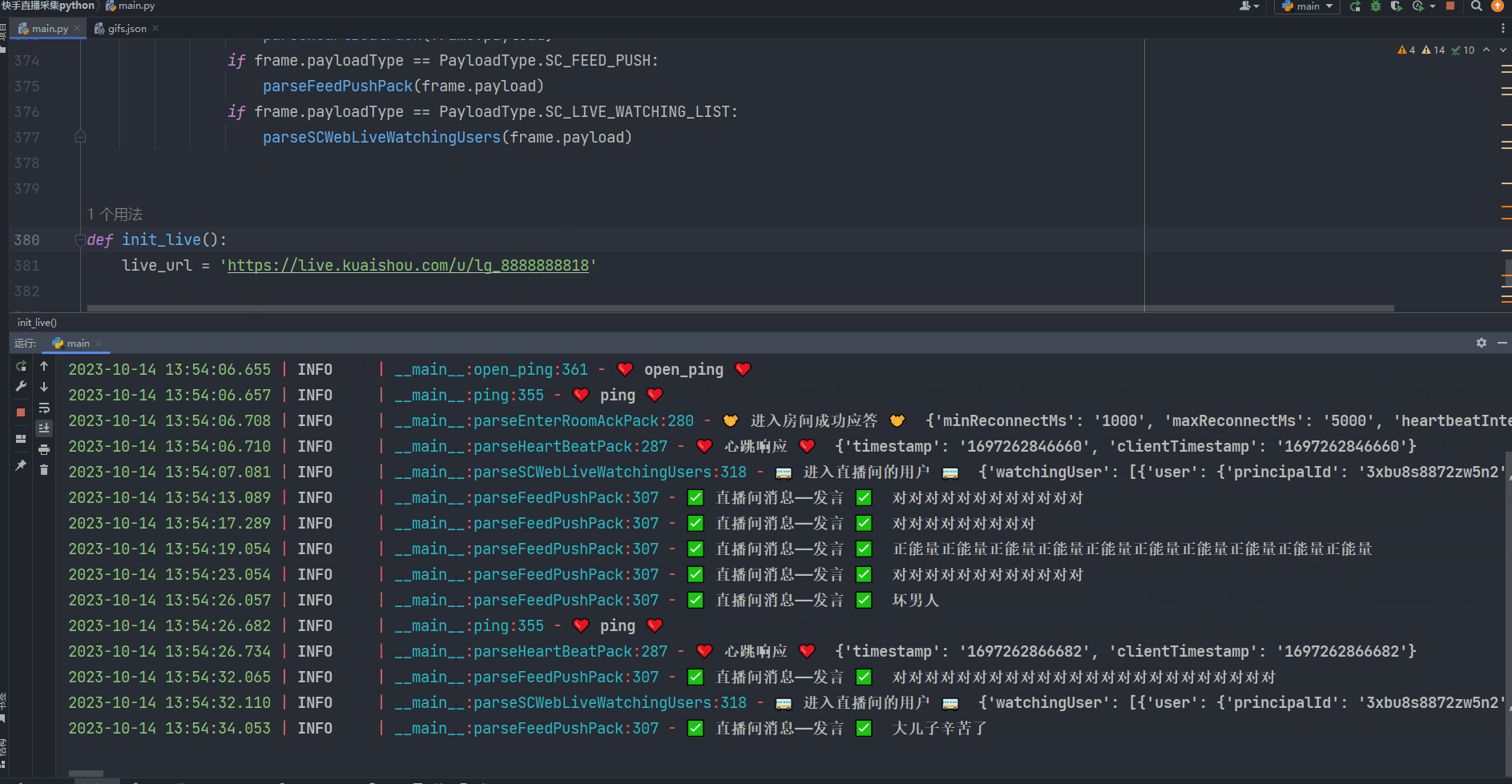
【python】爬取斗鱼直播照片保存到本地目录
一、导入必要的模块: 这篇博客将介绍如何使用Python编写一个爬虫程序,从斗鱼直播网站上获取图片信息并保存到本地。我们将使用requests模块发送HTTP请求和接收响应,以及os模块处理文件和目录操作。 如果出现模块报错 进入控制台输入ÿ…
网络爬虫与指纹浏览器:解析指纹浏览器对网络爬虫的作用
网络爬虫在信息搜集、数据挖掘等领域起着重要作用。然而,传统爬虫往往面临被目标网站封禁的风险。本文将介绍指纹浏览器对网络爬虫的作用,以及指纹浏览器如何帮助爬虫降低封禁风险。 网络爬虫面临的挑战
网络爬虫是一种自动化程序,用于从互联…
拼多多海量商品数据接口API 商品详情接口 商品价格主图接口
拼多多,作为中国最大的社交电商之一,提供了丰富的商品信息和海量的用户数据。对于广大开发者而言,如何快速、准确地获取这些数据,进而开发出各种创新应用,是他们关心的问题。本文将详细介绍拼多多海量商品数据接口API的…
Chromedriver安装教程【无需翻墙】
第一步
查看你当前Chrome浏览器的版本,如下图所示:
第二步
查看当前Chrome浏览器的版本号,如下图所示,版本 108.0.5359.125(正式版本) (64 位)中的,108就是我们的版本号。
第三…
数据采集,逆向学习,练手某国民应用
摘自个人印象笔记,图不完整可查看原笔记:https://app.yinxiang.com/fx/c021af2d-9b6f-42fc-af05-71cf7c929e1c某某源码获取
安装夜神模拟器,在模拟器上安装wx,打开“wx指数”小%程%序%用RE管理器找到根目录下的wxapkg后缀的文件&…
新业务场景如何个性化配置验证码?
验证码作为人机交互界面经常出现的关键要素,是身份核验、防范风险、数据反爬的重要组成部分,广泛应用网站、App上,在注册、登录、交易、交互等各类场景中发挥着巨大作用,具有真人识别、身份核验的功能,在保障账户安全方…

Python爬虫实战:抓取猫眼电影排行榜top100#4
爬虫专栏系列:http://t.csdnimg.cn/Oiun0
抓取猫眼电影排行
本节中,我们利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。requests 比 urllib 使用更加方便,而且目前我们还没有系统学习 HTML 解析库,所以这里就…

使用Python实现网页中图片的批量下载和水印添加保存
数字时代,图片已经成为我们生活中的一部分。无论是社交媒体上的照片,还是网页中的图片元素,我们都希望能够方便地下载并进行个性化的处理。 假设你是一位设计师,你经常需要从网页上下载大量的图片素材,并为这些图片添加…
爬虫项目实战:利用基于selenium框架的爬虫模板爬取豆瓣电影Top250
👋 Hi, I’m 货又星👀 I’m interested in …🌱 I’m currently learning …💞 I’m looking to collaborate on …📫 How to reach me … README 目录(持续更新中) 各种错误处理、爬虫实战及模…
淘宝商品历史价格查询接口(获取商品销量、历史价格)
item_history_price-获取商品历史价格信息
taobao.item_history_price 公共参数
名称类型必须描述keyString是调用key(获取key)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,ite…
python 爬虫 app爬取之charles的使用
专栏系列:http://t.csdnimg.cn/WfCSx
前言
前面介绍的都是爬取 Web 网页的内容。随着移动互联网的发展,越来越多的企业并没有提供 Web 网页端的服务,而是直接开发了 App,更多更全的信息都是通过 App 来展示的。那么针对 App 我们可以爬取吗?当然可以。
App 的爬取相比 …
Charles Windows10使用 证书安装 过期重设 证书加入到受信任根目录 配置访问WhatsApp
普通教程文档
抓包神器 Charles 使用教程详解 - 知乎
界面选项详细讲解
Charles的功能介绍与使用教程,一学就会,不信就来试试?
疑难杂症
由于CA 根证书不在“受信任的根证书颁发机构”存储区中,所以它不受信任
1、winr 运行…

采集SEO方法-添加链接段落
采集大量的文章数据,要想批量做SEO添加链接段落方法,可以使用简数采集器的处理规则实现。
简数采集器的一个处理规则,可以包含多种SEO方法,还可自由组合,强大灵活方便。
添加补充链接段落的SEO技巧:
1&a…

想要调用淘宝开放平台API,没有申请应用怎么办?
用淘宝自定义API接口可以访问淘宝开放平台API。
custom-自定义API操作
taobao.custom 公共参数
注册账号获取API请求地址
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称…

加速数据采集:用OkHttp和Kotlin构建Amazon图片爬虫
引言
曾想过轻松获取亚马逊上的商品图片用于项目或研究吗?是否曾面对网络速度慢或被网站反爬虫机制拦截而无法完成数据采集任务?如果是,那么本文将为您介绍如何用OkHttp和Kotlin构建一个高效的Amazon图片爬虫解决方案。
背景介绍
亚马逊&a…
如何实现批量获取电商数据自动化商品采集?如何利用电商数据API实现业务增长?
随着电子商务的快速发展,数据已经成为了电商行业最重要的资产之一。在这个数据驱动的时代,电商数据API(应用程序接口)的作用日益凸显。通过电商数据API,商家能够获取到大量关于消费者行为、产品表现、市场趋势等有价值…
网络服务器和客户端的编写
"""1、创建TCP服务器""" import socket # 用于网络通信 import threading # 创建多线程处理客户端请求 import time # 用于添加数据时用于延迟,模拟网路传输 # 建立TCP连接 s socket.socket(socket.AF_INET,socket.SOCK_STREAM)…
使用selenium抓取网易云音乐数据
今天通过一个简单的网易云音乐排行榜数据抓取与音乐下载实战案例,带着大家一起来学习如何抓取动态生成的页面内容。网易云音乐排行榜网址:https://music.163.com/#/discover/toplist,界面效果如下。 查看页面源代码,发现并没有这些…

Python爬虫爬取某会计师协会网站的指定文章(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…
1688 API分享:1688商品采集接口 1688关键字搜索接口
随着“无界零售”时代的到来,越来越多的企业开始寻求数字化转型,其中最重要的一个环节就是数据的互通和整合。而阿里巴巴旗下的B2B网站1688也推出了API接口,为企业间的数据交流提供了便利。电商API中有两个热门的接口,经常会被大家…
python爬虫实战——抖音
目录
1、分析主页作品列表标签结构
2、进入作品页前 判断作品是视频作品还是图文作品
3、进入视频作品页面,获取视频
4、进入图文作品页面,获取图片
5、完整参考代码
6、获取全部作品的一种方法 本文主要使用 selenium.webdriver(Firef…
python爬虫之app爬取-charles的使用
专栏系列:http://t.csdnimg.cn/WfCSx
前言
前面介绍的都是爬取 Web 网页的内容。随着移动互联网的发展,越来越多的企业并没有提供 Web 网页端的服务,而是直接开发了 App,更多更全的信息都是通过 App 来展示的。那么针对 App 我们可以爬取吗?当然可以。
App 的爬取相比 …

【Python爬虫项目实战一】获取Chatgpt3.5免费接口文末付代码(过Authorization认证)
目录 🚩前言🍑工具🍉分析流程🧅实战部分🧅🧅模拟登陆🧅🧅模拟提问请求🥒login方法🥒chatgpt方法🌰总结🚩前言
大家好!今天的目标是拿下Openmao的接口,他的接口内容和chatgpt3.5是一样的,它们的免责申明中写道:本站点基于外部API二次开发,仅供学习…

详解4种类型的爬虫技术
聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 增量抓取意…
Python爬虫学了到底有什么用?能带来更好的生活水平吗?
一、Python爬虫外包项目 网络爬虫最通常的的挣钱方式通过外包网站,做中小规模的爬虫项目,向甲方提供数据抓取,数据结构化,数据清洗等服务。新入行的程序员大多都会先尝试这个方向,直接靠技术手段挣钱,这…
提取作者用户名,帖子内容,回复时间
import re
import csv# 打开名为a1.txt的文件,并以只读模式(r)读取其内容。这里使用了UTF-8编码。
with open(网页源码a1.txt, r, encodingUTF-8) as f:# 读取文件的所有内容并赋值给变量source source f.read()# 使用正则表达式查找所有匹配region_header clea…
业务安全五重价值:防攻击、保稳定、助增收、促合规、提升满意度
目录
防范各类威胁攻击
保障业务的连续性和稳定性
保障业务的合规性
提升企业营收和发展
提升企业满意度和品牌知名度 2023年暑假被“票贩子”和“黄牛”攻陷。他们利用各种手段抢先预约名额,然后加价出售给游客,导致了门票供不应求的局面ÿ…

爬虫Python入门好学吗?学什么?
爬虫Python入门好学吗?学爬虫需要具备一定的基础,有编程基础学Python爬虫更容易学。但要多看多练,有自己的逻辑想法。用Python达到自己的学习目的才算有价值。如果是入门学习了解,开始学习不难,但深入学习有难度&#…
拼多多淘宝大量缓存商品数据用什么格式提供比较好?
众所周知,淘宝拼多多是我国主流的电商平台,其上有大量的商品数据。很多商家会通过API来访问他们的商品数据,根据API的调用次数收费。第三方数据公司提供电商数据接口API,采集实时数据。但是,在他们的服务器上有大量的缓…
电商数据接口API:品牌价格监控与数据分析的重要工具
一、引言
随着电子商务的快速发展,传统品牌企业越来越重视在线销售市场。为了在竞争激烈的市场环境中取得成功,企业需要实时掌握市场动态,了解自身产品的销售情况、价格趋势以及竞品信息。为了实现这一目标,各大电商平台…

告别StringUtil:使用Java 全新String API优化你的代码
前言 Java 编程语言的每一次重要更新,都引入了许多新功能和改进。 并且在String 类中引入了一些新的方法,能够更好地满足开发的需求,提高编程效率。
repeat(int count):返回一个新的字符串,该字符串是由原字符串重复指…
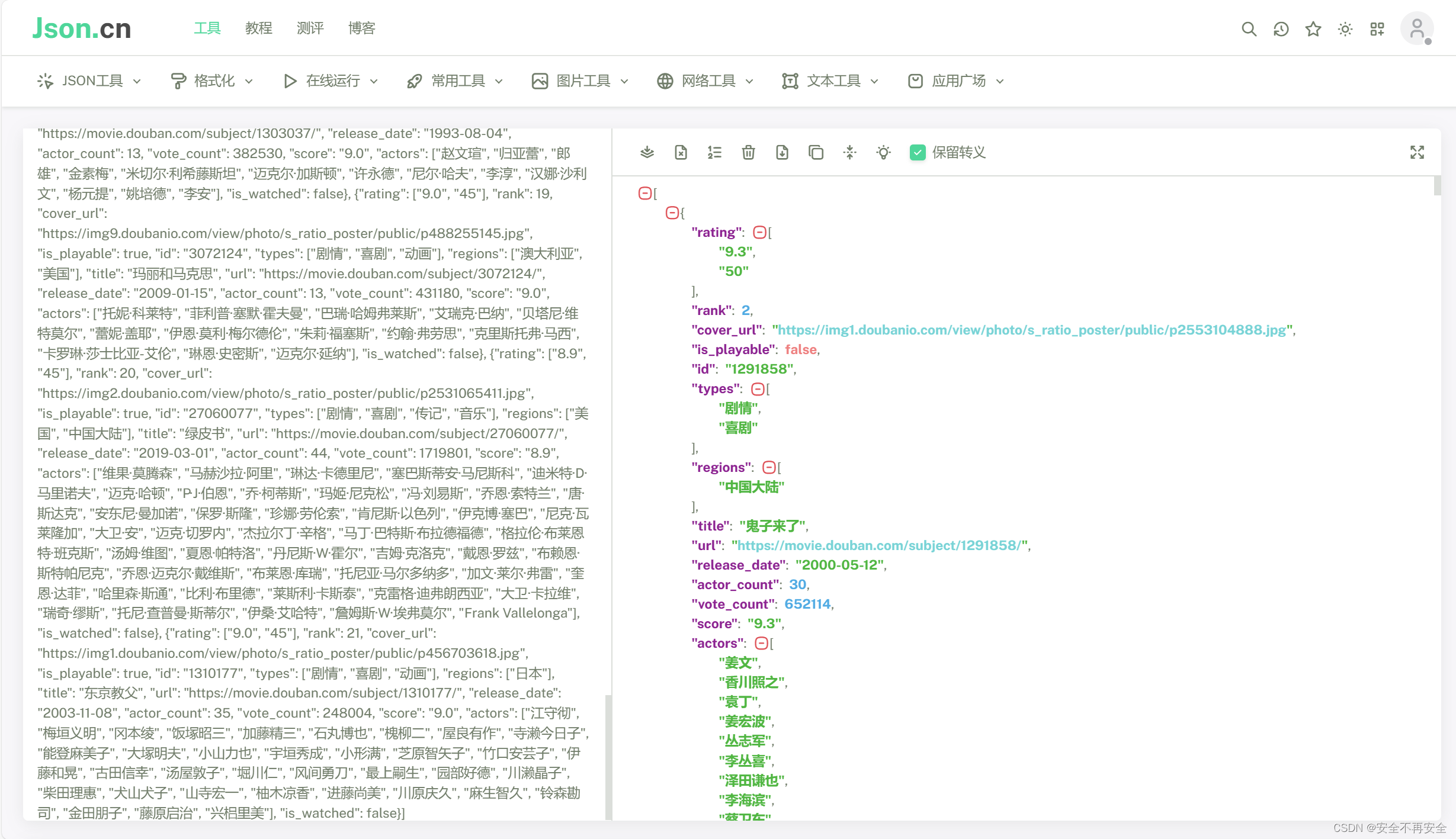
爬取豆瓣电影分类排行榜中的电影详情数据
进入界面,右键打开检测,选择网络 然后网页滚动条拉倒最下面使其刷出新的数据,然后查看数据包 编写代码
import requests
import jsonif __name__ __main__:get_url https://movie.douban.com/j/chart/top_listheaders {User-Agent:Mozil…
1688往微信小程序自营商城铺货商品采集API接口
一、背景介绍
随着移动互联网的快速发展,微信小程序作为一种新型的电商形态,正逐渐成为广大商家拓展销售渠道、提升品牌影响力的重要平台。然而,对于许多传统企业而言,如何将商品信息快速、准确地铺货到微信小程序自营商城是一个…

Swift使用Embassy库进行数据采集:热点新闻自动生成器
概述
爬虫程序是一种可以自动从网页上抓取数据的软件。爬虫程序可以用于各种目的,例如搜索引擎、数据分析、内容聚合等。本文将介绍如何使用Swift语言和Embassy库编写一个简单的爬虫程序,该程序可以从新闻网站上采集热点信息,并生成一个简单…
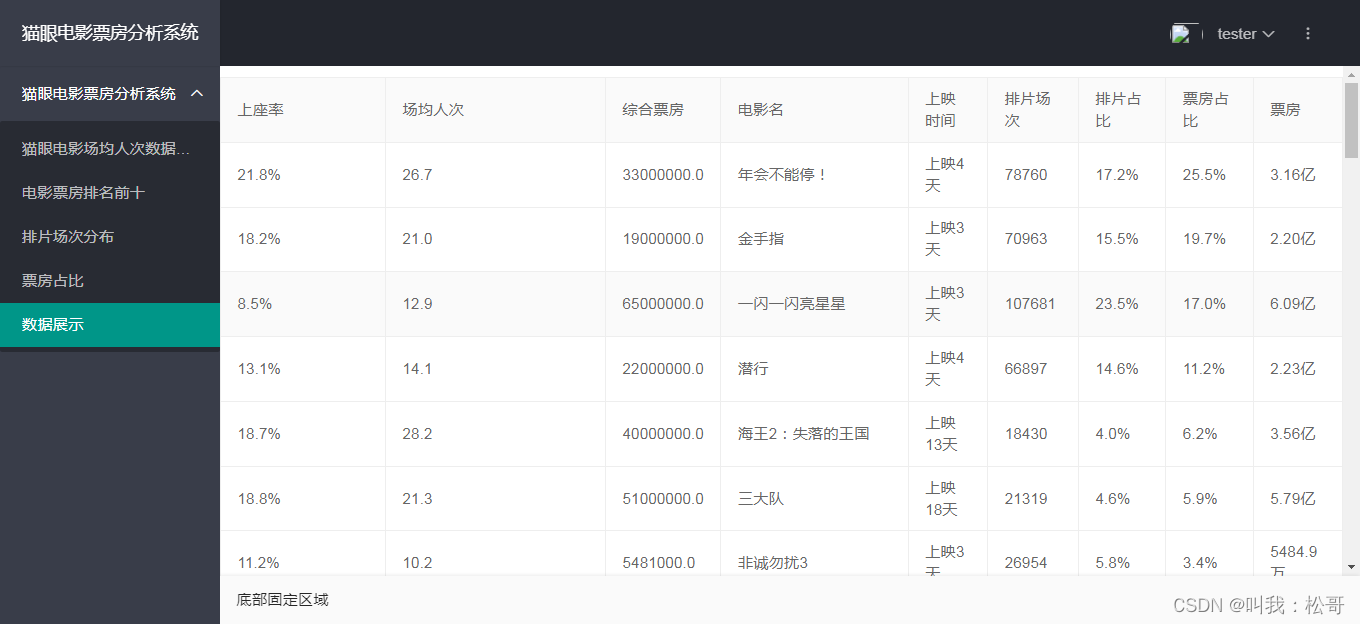
基于Python flask的猫眼电影票房数据分析可视化系统,可以定制可视化
技术方案
猫眼电影票房数据分析可视化系统是基于Python Flask框架开发的一款用于分析和展示猫眼电影票房数据的Web应用程序。该系统利用Flask提供了一个简单而强大的后端框架,结合Request库进行网络爬虫获取猫眼电影票房数据,并使用Pyecharts进行可视化…

阿里巴巴国际站商品采集商品信息抓取API免费测试入口(英文商品信息跨境电商商品信息自动化抓取)
alibaba.item_get 获取商品详情信息
alibaba.item_search 关键字搜索商品列表
进入API测试页,获取key和密钥
公共参数
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称…

hgame202301 week1 web writeup
目录前言一、Classic Childhood Game二、Become A Member三、Show Me Your Beauty四、Guess Who I Am后记前言
记录2023年1月的hgame比赛week1的web题 第一周还是比较简单的,除了那个涉及到网页爬虫的题一度不会写(本「待入门」选手还是太菜了
一、Cla…
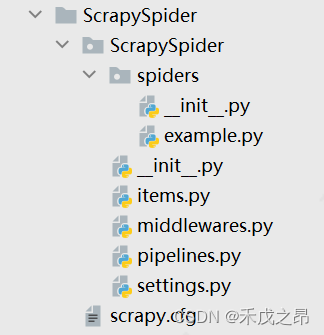
【Python_Scrapy学习笔记(二)】创建Scrapy爬虫项目
创建Scrapy爬虫项目
前言
本文主要介绍如何创建并运行 Scrapy 爬虫项目。
正文
1、创建 Scrapy 框架 Scrapy 框架提供了 scrapy 命令用来建立 Scrapy 工程,在终端 terminal 中输入以下命令: scrapy startproject 自定义的项目名称创建好爬虫项目文件…

【js逆向实战】某sakura动漫视频逆向
写在前面
再写一个逆向实战,后面写点爬虫程序来实现一下。
网站简介与逆向目标
经典的一个视频网站,大多数视频网站走的是M3U8协议,就是一个分段传输,其实这里就有两个分支。 通过传统的m3u8协议,我们可以直接进行分…

【Python_Scrapy学习笔记(七)】基于Scrapy框架实现数据持久化
基于 Scrapy框架实现数据持久化
前言
本文中介绍 如何基于 Scrapy 框架实现数据持久化,包括 Scrapy 数据持久化到 MySQL 数据库、MangoDB数据库和本地 csv 文件、json 文件。
正文
1、Scrapy数据持久化到MySQL数据库 在 settings.py 中定义 MySQL 相关变量 # 定…
WebScraper网页数据爬取可视化工具使用(无需编码)
前言
Web Scraper 是一个浏览器扩展,可以实现无需编码即可爬取网页上的数据。只需按照规则进行配置,即可实现一键爬取导出数据。
安装
进入Google应用商店安装此插件,安装步骤如下: 进入Google应用商店需要外网VPN才能访问&…
爬虫逆向非对称加密和对称加密案例
注意!!!!某XX网站逆向实例仅作为学习案例,禁止其他个人以及团体做谋利用途!!! 案例--aHR0cHM6Ly9jcmVkaXQuaGxqLmdvdi5jbi94eWdzL3l6d2ZzeHF5bWQv 第一步:分析页面、请求…
基于大数据的汽车信息可视化分析预测与推荐系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 本项目通过集成网络爬虫技术,实时获取海量汽车数据;运用先进的ARIMA时序建模算法对数据进行深度挖掘和分析;结合flask web系统和echarts可视化工具,…
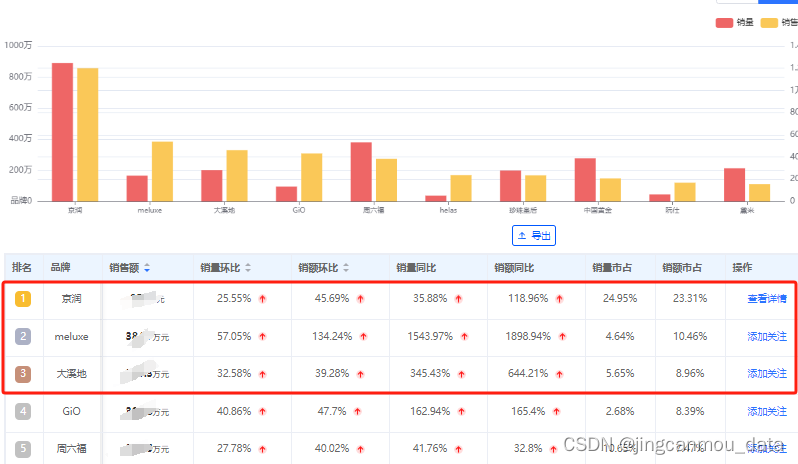
2月珍珠饰品电商数据分析:价格翻倍,销售额暴增140%!
珍珠饰品这两年受到国内消费者的追捧,这股热潮随着电商直播的快速发展延续至今。与此同时,年轻人群体正成为珍珠消费的主力军,他们在各大直播间频繁亮相,以实际购买力展现了对珍珠饰品的热爱与追捧。
今年2月份,珍珠饰…

超越常规:用PHP抓取招聘信息
在人力资源管理方面,有效的数据采集可以为公司提供宝贵的人才洞察。通过分析招聘网站上的职位信息,人力资源专员可以了解市场上的人才供给情况,以及不同行业和职位的竞争状况。这样的数据分析有助于企业制定更加精准的招聘策略,从…

Requests-get方法的使用
Requests-get方法使用 打开网页使用代码获取页面内容查看结果页面格式修改 爬取书名完整代码以及注释代码注释 翻页查询所有 以https://books.toscrape.com/网站为例: 打开网页
先把网页打开,然后右键检查,找到网络一栏,这个时候…

【实战】爬虫风险业务防控 | 国际航班上,小“票代”在疯狂倒卖高价票
目录
乘坐国际航班,躲不开的“票代”
小“票代”的网络爬虫与高价票
某公司国际航班遭遇大量爬虫攻击
基于爬虫风险的分析与防控建议 顶象防御云业务安全情报中心监测发现,某航空国际航班,遭遇恶意网络爬虫的持续攻击。高峰时期ÿ…
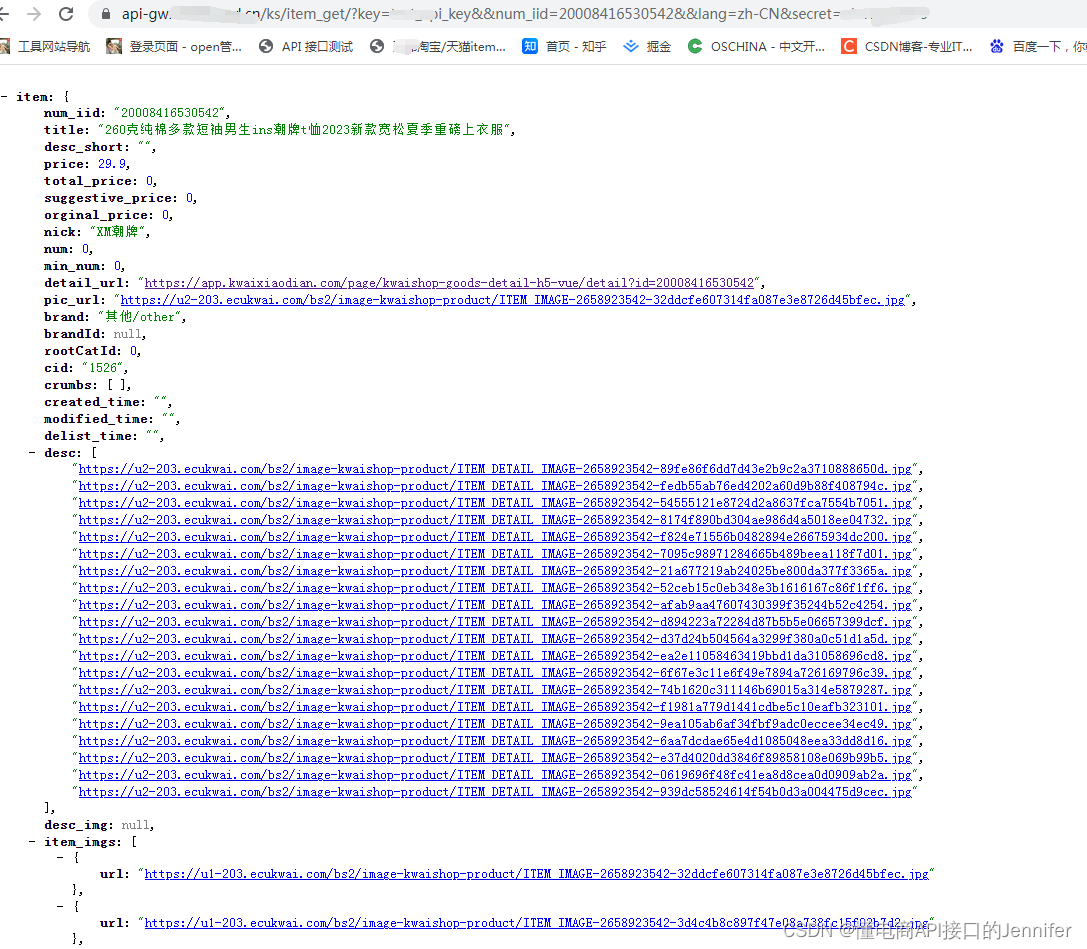
快手商品详情数据API 抓取快手商品价格、销量、库存、sku信息
快手商品详情数据API是用来获取快手商品详情页数据的接口,请求参数为商品ID,这是每个商品唯一性的标识。返回参数有商品标题、商品标题、商品简介、价格、掌柜昵称、库存、宝贝链接、宝贝图片、商品SKU等。
接口名称:item_get
公共参数
名…
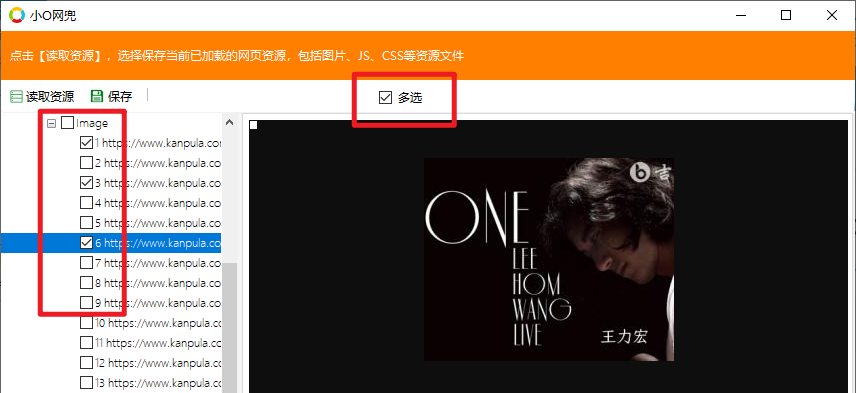
分享图片 | 快速浏览网页资源,批量保存、一键分享图片
前言
小伙伴学习吉他,有时需要在互联网搜索曲谱资源,而多数曲谱均为图片,并且为多页,在电脑上显示练习很不方便,需要停下来点击鼠标进行翻页,影响练习的连贯性。
为了解决上述问题,通常把图片…
Python最新面试题汇总及答案
一、基础部分
1、什么是Python?为什么它会如此流行?Python是一种解释的、高级的、通用的编程语言。Python的设计理念是通过使用必要的空格与空行,增强代码的可读性。它之所以受欢迎,就是因为它具有简单易用的语法
2、为什么Pytho…
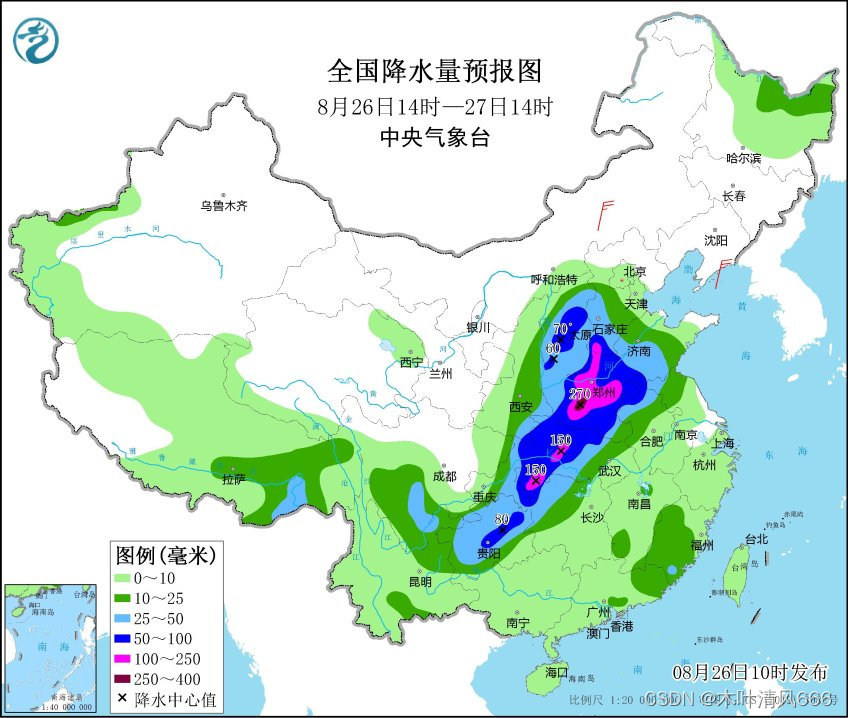
【python爬虫】中央气象局预报—静态网页图像爬取练习
静态网页爬取练习 中央气象局预报简介前期准备步骤Python爬取每日预报结果—以降水为例 中央气象局预报简介 中央气象台是中国气象局(中央气象台)发布的七天降水预报页面。这个页面提供了未来一周内各地区的降水预报情况,帮助人们了解即将到来…
淘宝商品销量接口API更新(总销+精准月销API)
不少客户有获取淘宝商品销量的需求,淘宝商品销量接口主要用于以下业务场景。有不齐全的欢迎大家补充。
库存管理:商家可以通过接口获取到实时的销量信息,更好地进行库存管理。供应链计划:商家可以通过接口了解到商品的销售趋势&a…

获取商品SKU信息API调用代码展示、请求参数和返回值说明
SKU是什么意思
最小存货单位(SKU),全称为stock keeping unit,即库存进出计量的基本单元,可以是以件、盒、托盘等为单位。SKU这是对于大型连锁超市DC(配送中心)物流管理的一个必要的方法。现在已…
【python爬虫】16.爬虫知识点总结复习
文章目录 前言爬虫总复习工具解析与提取(一)解析与提取(二)更厉害的请求存储更多的爬虫更强大的爬虫——框架给爬虫加上翅膀 爬虫进阶路线指引解析与提取 存储数据分析与可视化更多的爬虫更强大的爬虫——框架项目训练 反爬虫应对…
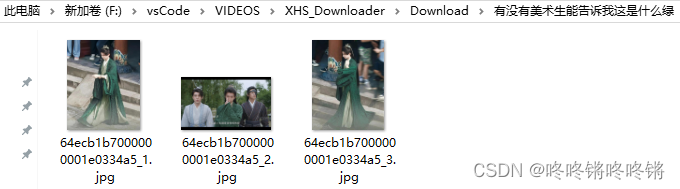
Python爬虫:下载小红书无水印图片、视频
该代码只提供学习使用,该项目是基于https://github.com/JoeanAmier/XHS_Downloader的小改动
1.下载项目
git clone https://github.com/zhouayi/XHS_Downloader.git2.找到需要下载的文章的ID 写入main.py中
3.下载
python main.py最近很火的莲花楼为例<嘿嘿…

懂点心理学 - 踢猫效应
懂点心理学,生活工作两不误~
什么是踢猫效应 某公司董事长为了重整公司事务,许诺自己将早到晚归。有一次,他在家看报太入迷以至于忘记了时间,为了不迟到,他在公路上超速驾驶,结果被警察开了罚单…
【工作记录】基于spiderflow+ocr实现图片验证码识别@20230906
声明: 本文引用的网站仅用于演示,如侵删。
背景
这两天收到运营同事一个关于需要登录的网站的数据爬取需求,登录同时需要填入图片验证码。 经过多次尝试,结合百度OCR可以完成图片验证码的获取和识别,特此记录。 希望能帮助到需要…
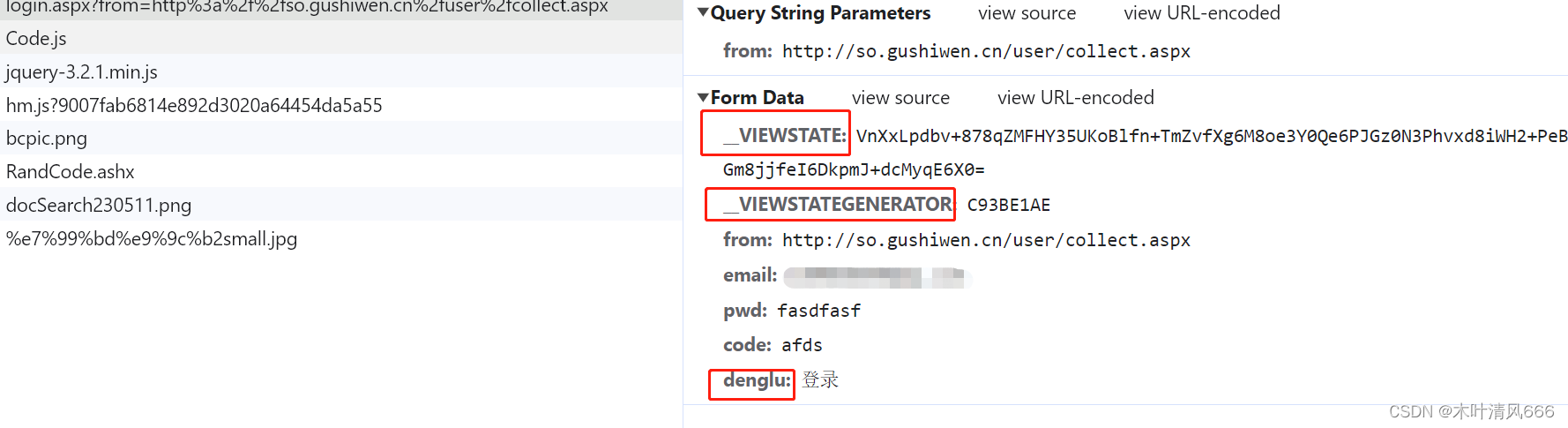

Python爬虫在电商数据获取与分析中的应用
前言
随着电商平台的兴起,越来越多的人开始在网上购物。而对于电商平台来说,商品信息、价格、评论等数据是非常重要的。因此,抓取电商平台的商品信息、价格、评论等数据成为了一项非常有价值的工作。本文将介绍如何使用Python编写爬虫程序&a…
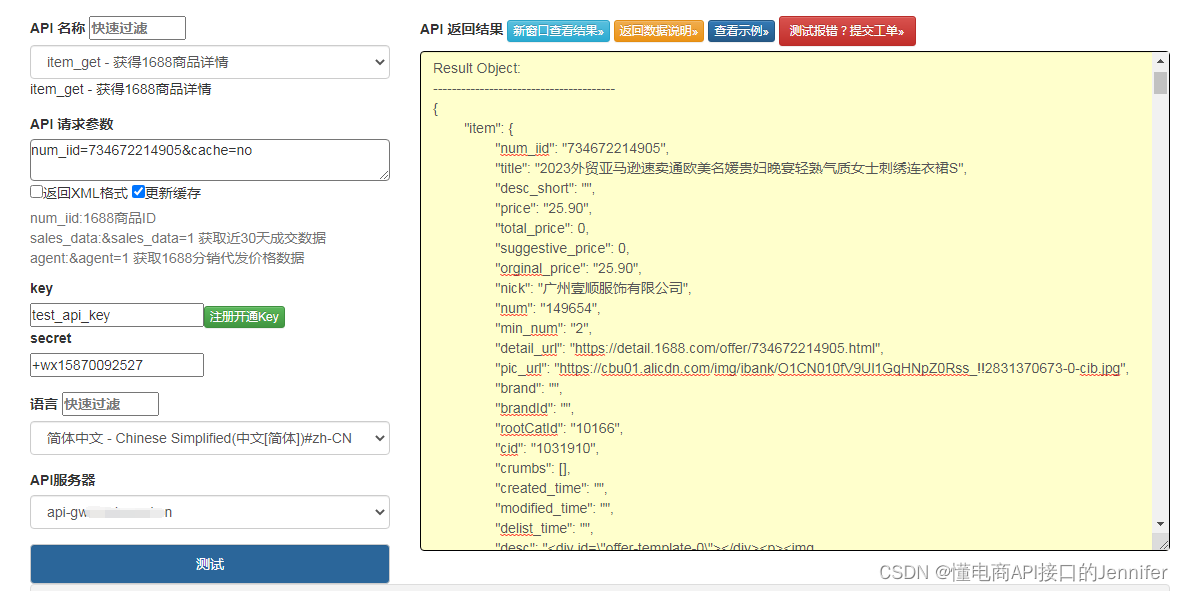
实现自动化获取1688商品详情数据接口经验分享
获取电商平台商品详情数据,主要用过的是爬虫技术,过程比较曲折,最终结果是好的。我将代码都封装在1688.item_get接口中,直接调用此接口可以一步抓取。
展示一下获取成功示例:
1688商品详情页展示 传入商品ID调用item…

python爬虫实战——小红书
目录
1、博主页面分析
2、在控制台预先获取所有作品页的URL
3、在 Python 中读入该文件并做准备工作
4、处理图文类型作品
5、处理视频类型作品
6、异常访问而被中断的现象
7、完整参考代码 任务:在 win 环境下,利用 Python、webdriver、JavaS…

猿人学刷题系列(第一届比赛)——第三题
题目:抓取下列5页商标的数据,并将出现频率最高的申请号填入答案中 地址:https://match.yuanrenxue.cn/match/3
本题主要考察请求逻辑,可以借助fiddler或Charles等抓包工具进行分析。首先通过浏览器来简单进行请求逻辑分析。 从抓…

反爬虫机制与反爬虫技术(一)
反爬虫机制与反爬虫技术一 1、网络爬虫的法律与道德问题2、反爬虫机制与反爬虫技术2.1、User-Agent伪装2.2、代理IP2.3、请求频率控制2.4、动态页面处理2.5、验证码识别3、反爬虫案例:豆瓣电影Top250爬取3.1、爬取目标3.2、库(模块)简介3.3、翻页分析3.4、发送请求3.5、提取…

爬虫采集如何解决ip被限制的问题呢?
在进行爬虫采集的过程中,很多开发者会遇到IP被限制的问题,这给采集工作带来了很大的不便。那么,如何解决这个问题呢?下面我们将从以下几个方面进行探讨。 一、了解网站的反爬机制 首先,我们需要了解目标网站的反爬机制…
关于爬虫API常见的技术问题和解答
随着互联网的快速发展,数据获取变得越来越重要。爬虫API作为一种高效的数据获取手段,被广泛应用于各种场景。然而,在实际使用过程中,我们经常会遇到一些技术问题。本文将详细介绍爬虫API的常见技术问题及相应的解决方案。
一、爬…
多平台商品采集——API接口:支持淘宝、天猫、1688、拼多多等多个电商平台的爆款、销量、整店商品采集和淘客功能
item_get-获得淘宝商品详情
item_get_app-获得淘宝app商品详情原数据
item_get_pro-获得淘宝商品详情高级版
item_search-按关键字搜索淘宝商品
item_search_img-按图搜索淘宝商品(拍立淘)
item_search_shop-获得店铺的所有商品
API请求地址
公共…

Go语言多线程爬虫万能模板它来了!
对于长期从事爬虫行业的技术员来说,通过技术手段实现抓取海量数据并且做到可视化处理,我在想如果能写一个万能的爬虫模板,后期遇到类似的工作只要套用模板就能解决大部分的问题,如此提高工作效率何乐而不为? 以下是一个…
大数据项目——基于Django协同过滤算法的房源可视化分析推荐系统的设计与实现
大数据项目——基于Django协同过滤算法的房源可视化分析推荐系统的设计与实现
技术栈:大数据爬虫/机器学习学习算法/数据分析与挖掘/大数据可视化/Django框架/Mysql数据库
本项目基于 Django框架开发的房屋可视化分析推荐系统。这个系统结合了大数据爬虫、机器学习…
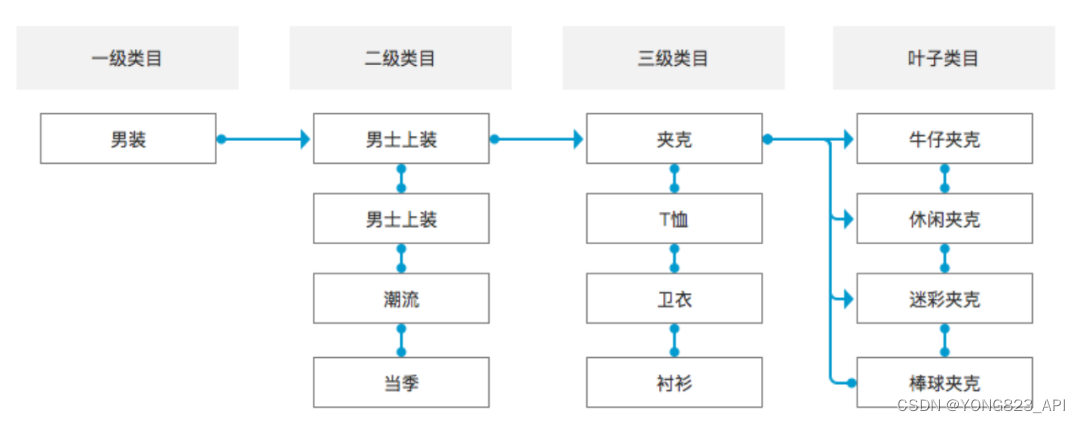
淘宝类目信息API接口获取淘宝商品分类信息API调用说明(含APIkey密钥)
cat_get-获得淘宝分类详情
item_cat_get-获得淘宝商品类目
公共参数
名称类型必须描述keyString是调用key(点此获取)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,item_search_…

从零开始制作一个Douban图像下载器:Wt库的基础知识和操作指南
引言
欢迎来到本文,如果你希望从豆瓣下载海量的高清图像、学习使用现代C web应用程序框架Wt库开发web应用程序,或者了解如何利用代理IP和多线程技术提高爬虫效率和稳定性,那么你来对地方了。在接下来的内容中,我们将为你提供一个…

基于Python的微博热点李佳琦忒网友话题的评论采集和情感分析的方法,利用情感分析技术对评论进行情感倾向性判断
1 引言
1.1背景
介绍了基于Python的微博热点李佳琦忒网友话题的评论采集和情感分析的方法。首先,使用Python编写程序实现微博评论的采集,通过API或爬虫方式获取相关话题下的评论数据。然后,对采集到的评论数据进行预处理,包括分…
100天精通Python(实用脚本篇)——第115天:基于selenium实现反反爬策略之隐藏浏览器指纹特征
文章目录 专栏导读1. 什么是浏览器指纹?2. 爬虫隐藏浏览器指纹特征的好处?3. 手动打开浏览器指纹情况4. 无界面模式打开浏览器5. 脚本隐藏浏览器指纹特征 专栏导读
🔥🔥本文已收录于《100天精通Python从入门到就业》:…

如何知道调用电商API是否成功返回数据?查看错误码解释
在API调用过程中,系统可能会返回一些错误码。错误码能够帮助开发者快速准确地了解出现的异常情况。错误码的含义通常涉及到请求参数不合法、认证失败、服务器内部错误等各种问题,它们提供了有关API调用失败的信息和上下文,在错误排查和修复时…
Python爬虫-使用代理伪装IP
爬虫系列:http://t.csdnimg.cn/WfCSx
前言
我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常抓取数据,一切看起来都是那么的美好,然而一杯茶的功夫可能就会出现错误,比如 403 Forbidden&…
為什麼使用海外動態代理IP進行網路爬蟲?
網路爬蟲作為獲取網路數據的重要工具,其重要性不言而喻。但隨著網站反爬策略的日益嚴格,爬蟲任務變得愈發困難,不過海外動態代理IP可以很好地解決這一問題。本文將詳細闡釋動態代理IP在爬蟲中的應用,以及如何使用動態代理IP提升爬…
电商上货软件|一键复制搬家|快速铺货必备API
电商上货软件中必不可少的API包括:
item_search 关键字采集商品列表item_get 获取商品详情信息item_search_tmall 按关键字搜索天猫商品item_search_pro 高级关键字搜索淘宝商品item_search_img 按图搜索淘宝商品(拍立淘)item_search_shop 获…

python 爬虫学习
Beautiful Soup 4.4.0 文档
参考《Python 网络数据采集》
爬虫初步
安装BeautifulSoup( 非python 的标准库,需要单独安装)
linux环境下:
sudo apt-get install python-bs4
Mac环境下:
sudo easy_install pip
pip是一个包管理器
pip install be…
1688商品采集API轻松实现商品上传上货搬家
item_get-获得1688商品详情
公共参数
请求地址: 1688/item_get
名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,…
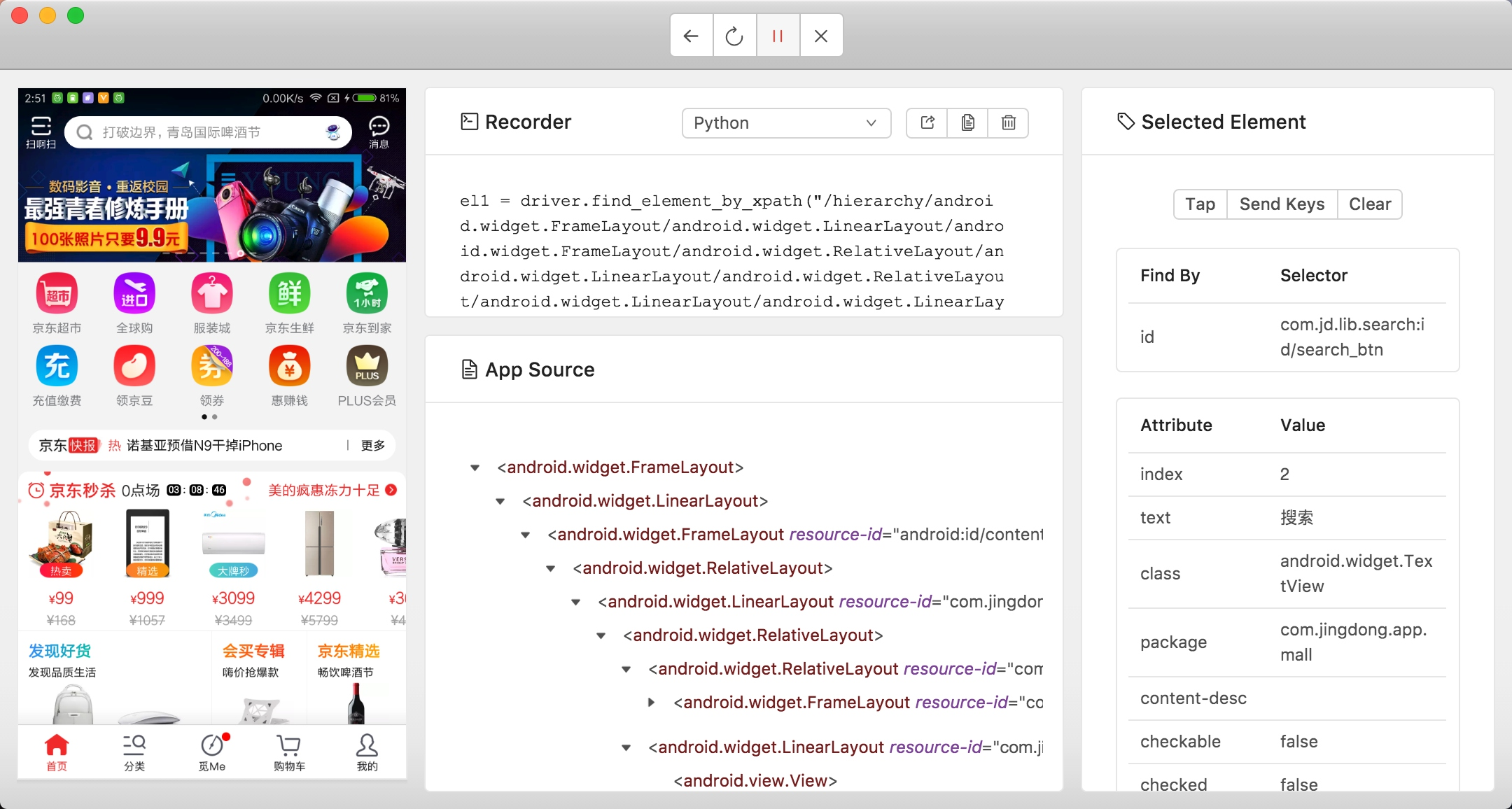
python爬虫 Appium+mitmdump 京东商品
爬虫系列:http://t.csdnimg.cn/WfCSx
前言
我们知道通过Charles进行抓包可以发现其参数相当复杂,Form 表单有很多加密参数。如果我们只用 Charles 探测到这个接口链接和参数,还是无法直接构造请求的参数,构造的过程涉及一些加密…

Python爬虫实战—探索某网站电影排名
文章目录 Python爬虫实战—探索某网站电影排名准备工作编写爬虫代码代码解析运行情况截图进一步优化和说明完整代码总结 说明:本案例以XXX网站为例,已隐去具体网站名称与地址。 Python爬虫实战—探索某网站电影排名
网络爬虫是一种自动化程序࿰…
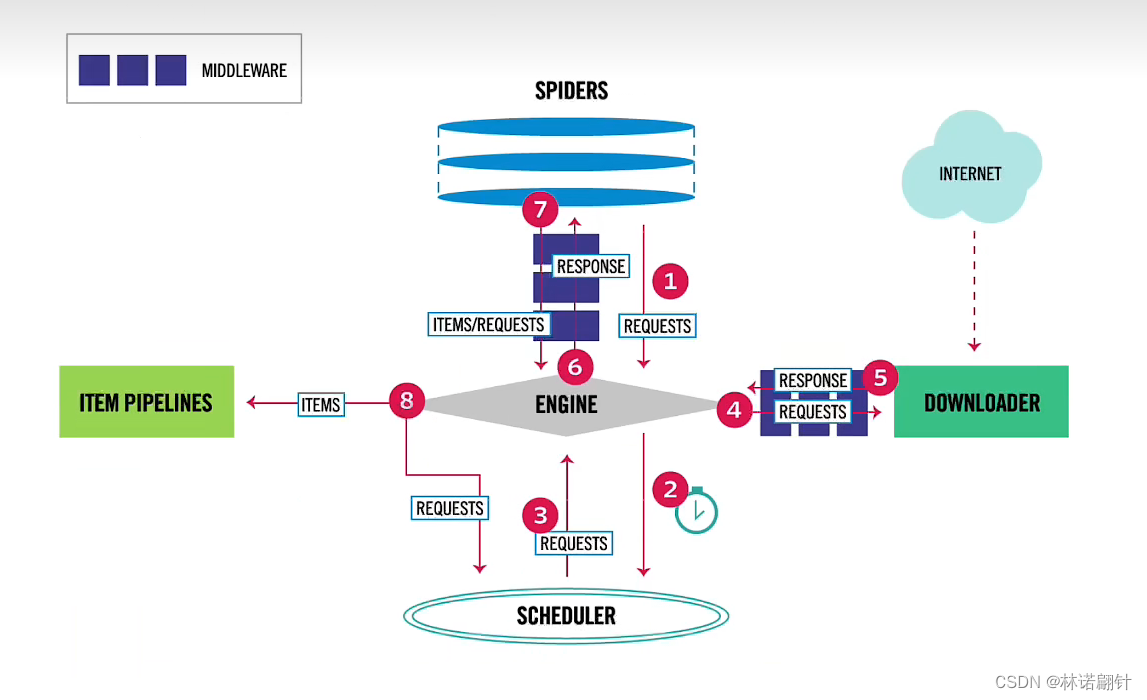
Scrapy和Selenium整合(一文搞定)
文章目录 前言一、开始准备1. 包管理和安装chrome驱动2. 爬虫项目的创建(举个栗子)3. setting.py的配置 二、代码演示1. 主爬虫程序2. 中间件的配置3. 定义item对象4. 定义管道 总结 前言
scrapy和selenium的整合使用 先定个小目标实现万物皆可爬&#…
BOSS直聘自动投简历聊天机器人的实现过程
这两年疫情,公司业务越来越差,必须得准备后路了,每天睡前都会在直聘上打一遍招呼,一直到打哈欠有睡意为止...,这样持续了一周,发现很难坚持,身为一名资深蜘蛛侠,怎么能这样下去呢?于…
爬取斗图网页前五页的图片
单线程爬取
import requests
from lxml import etree
import os
import time
def tupi_url():for tape in range(1, 4):url fhttps://www.pkdoutu.com/article/list/?page{tape}headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML…
起薪2万的爬虫工程师,Python需要学到什么程度才可以就业?
爬虫工程师的的薪资为20K起,当然,因为大数据,薪资也将一路上扬。那么,Python需要学到什么程度呢?今天我们来看看3位前辈的回答。
1、前段时间快要毕业,而我又不想找自己的老本行Java开发了,所以面了很多P…
(十)python网络爬虫(理论+实战)——正则表达式再讨论、常用正则表达式整理
系列文章目录 (1)python网络爬虫—快速入门(理论+实战)(一) (2)python网络爬虫—快速入门(理论+实战)(二) (3) python网络爬虫—快速入门(理论+实战)(三) (4)python网络爬虫—快速入门(理论+实战)(四) (5)
【爬虫基础】第1讲 网络爬虫基本知识
什么是网络爬虫 网络爬虫(Web crawler)是一种自动化程序,用于在互联网上收集信息。它可以通过扫描和解析网页的超链接,自动访问网页并抓取所需的数据。网络爬虫常用于搜索引擎和数据采集工具中。
作用
通过有效的爬虫手段批量采…

作者开发的爬取妹子图片Python项目,值得你收藏拥有
最好的学习方法在于实践,学习编程语言Python,也是同样的道理。本文讲解自己开发的一个项目,实现爬取妹子图片,所用的Python知识点以及模块,可以关注参考作者公众号的Python语言合集。
—、前情介绍
1.1 涉及模块
本…
爬虫案例-使用Session登录指定网站(JS逆向AES-CBC加密+MD5加密)
总体概览:使用Session登录该网站,其中包括对password参数进行js逆向破解 (涉及加密:md5加密AES-CBC加密)
难度:两颗星
目标网址:aHR0cHM6Ly93d3cuZnhiYW9nYW8uY29tLw
下面文章将分为四个部分…

Go编程:使用 Colly 库下载Reddit网站的图像
概述
Reddit是一个社交新闻网站,用户可以发布各种主题的内容,包括图片。本文将介绍如何使用Go语言和Colly库编写一个简单的爬虫程序,从Reddit网站上下载指定主题的图片,并保存到本地文件夹中。为了避免被目标网站反爬,…
Python爬虫之自动化测试Selenium#7
爬虫专栏:http://t.csdnimg.cn/WfCSx
前言
在前一章中,我们了解了 Ajax 的分析和抓取方式,这其实也是 JavaScript 动态渲染的页面的一种情形,通过直接分析 Ajax,我们仍然可以借助 requests 或 urllib 来实现数据爬取…

Go语言网络爬虫工程经验分享:pholcus库演示抓取头条新闻的实例
网络爬虫是一种自动从互联网上获取数据的程序,它可以用于各种目的,如数据分析、信息检索、竞争情报等。网络爬虫的实现方式有很多,不同的编程语言和框架都有各自的优势和特点。在本文中,我将介绍一种使用Go语言和pholcus库的网络爬…